
1. 基础语法
1.1 关键词和类型
Java 关键字
下面列出了 Java 关键字。这些关键字不能用于常量、变量、和任何标识符的名称。
| 类别 | 关键字 | 说明 |
|---|---|---|
| 访问控制 | private | 私有的 |
| protected | 受保护的 | |
| public | 公共的 | |
| 类、方法和变量修饰符 | abstract | 声明抽象 |
| class | 类 | |
| extends | 扩充,继承 | |
| final | 最终值,不可改变的 | |
| implements | 实现(接口) | |
| interface | 接口 | |
| native | 本地,原生方法(非 Java 实现) | |
| new | 新,创建 | |
| static | 静态 | |
| strictfp | 严格,精准 | |
| synchronized | 线程,同步 | |
| transient | 短暂 | |
| volatile | 易失 | |
| 程序控制语句 | break | 跳出循环 |
| case | 定义一个值以供 switch 选择 | |
| continue | 继续 | |
| default | 默认 | |
| do | 运行 | |
| else | 否则 | |
| for | 循环 | |
| if | 如果 | |
| instanceof | 实例 | |
| return | 返回 | |
| switch | 根据值选择执行 | |
| while | 循环 | |
| 错误处理 | assert | 断言表达式是否为真 |
| catch | 捕捉异常 | |
| finally | 有没有异常都执行 | |
| throw | 抛出一个异常对象 | |
| throws | 声明一个异常可能被抛出 | |
| try | 捕获异常 | |
| 包相关 | import | 引入 |
| package | 包 | |
| 基本类型 | boolean | 布尔型 |
| byte | 字节型 | |
| char | 字符型 | |
| double | 双精度浮点 | |
| float | 单精度浮点 | |
| int | 整型 | |
| long | 长整型 | |
| short | 短整型 | |
| 变量引用 | super | 父类,超类 |
| this | 本类 | |
| void | 无返回值 | |
| 保留关键字 | goto | 是关键字,但不能使用 |
| const | 是关键字,但不能使用 | |
| null | 空 |
byte:
- byte 数据类型是8位、有符号的,以二进制补码表示的整数;
- 最小值是 -128(-2^7);
- 最大值是 127(2^7-1);注意-1
- 默认值是 0;
- byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;
- 例子:byte a = 100,byte b = -50。
short :16位 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一
int:32位
long:64位 非常需要注意,如果直接量超过int的21亿多少的最大值,long i = 888888888888L;必须在结尾加上L确保直接量是long类型,不然无法通过编译。
float:**32位不能表示精确的值,如货币**
double:64位不能表示精确的值,如货币
浮点数的不精确性:
小数是连续的,任意两个小数之间都有无穷多个数字。
浮点表示法不能穷尽这些数字,只能返回一个近似值。
解决方案:
java.math.BigDecimal,是 Java 内置的类,用于精确计算。
boolean:
- boolean数据类型表示一位的信息;
- 只有两个取值:true 和 false;
char:
- char类型是一个单一的 16 位 Unicode 字符;
- 最小值是 \u0000(即为0);
- 最大值是 \uffff(即为65,535);
- char 数据类型可以储存任何字符;
- 例子:char letter = ‘A’;。以下是类的成员变量不初始化的默认值
| 数据类型 | 默认值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0f |
| double | 0.0d |
| char | ‘u0000’ |
| String (or any object)注意首字母大写这是引用数据类型默认值null | null |
| boolean | false |
引用类型 vs 基本类型
| 特性 | 引用类型 | 基本类型 |
|---|---|---|
| 存储内容 | 对象地址 | 实际值 |
| 内存位置 | 栈存引用,堆存对象 | 栈存值 |
| 默认值 | null | 0/false等 |
| 示例 | String, Array, Object | int, double, boolean |
Java中的引用数据类型主要有:(除了基本应该都是引用)
- 类类型(自定义类、内置类)
- 接口类型(Interface)
- 数组类型(Array)
- 枚举类型(Enum)
- 注解类型(Annotation)
所有引用类型的变量存储的都是对象的地址引用,而不是对象本身。
数据类型转换规则
整型、实型(常量)、字符型数据可以混合运算。运算中,不同类型的数据先转化为同一类型,然后进行运算。
转换从低级到高级。
低 ------------------------------------> 高`
byte,short,char < int < long < float < double
注意float是优先于long的
数据类型转换必须满足如下规则:
- 不能对boolean类型进行类型转换。
- 不能把对象类型转换成不相关类的对象。
- 在把容量大的类型转换为容量小的类型时必须使用强制类型转换。
- 转换过程中可能导致溢出或损失精度,例如:
int i = 128; byte b = (byte)i;
因为 byte 类型是 8 位,最大值为127,所以当 int 强制转换为 byte 类型时,值 128 时候就会导致溢出。
浮点数到整数的转换是通过舍弃小数得到,而不是四舍五入,例如:
(int)23.7 == 23;
(int)-45.89f == -45
局部变量要求
局部变量声明在方法、构造方法或者语句块中,必须初始化使用。
1.2 运算符
算术运算符
算术运算符用在数学表达式中,它们的作用和在数学中的作用一样。下表列出了所有的算术运算符。
表格中的实例假设整数变量A的值为10,变量B的值为20:
| 操作符 | 描述 | 例子 |
|---|---|---|
| + | 加法 – 相加运算符两侧的值 | A + B 等于 30 |
| – | 减法 – 左操作数减去右操作数 | A – B 等于 -10 |
| * | 乘法 – 相乘操作符两侧的值 | A * B等于200 |
| / | 除法 – 左操作数除以右操作数 | B / A等于2 |
| % | 取余 – 左操作数除以右操作数的余数 | B%A等于0 |
| ++ | 自增: 操作数的值增加1 | B++ 或 ++B 等于 21(区别详见下文) |
| — | 自减: 操作数的值减少1 | B– 或 –B 等于 19(区别详见下文) |
b=1
b++=1,++b=2
关系运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| == | 检查如果两个操作数的值是否相等,如果相等则条件为真。 | (A == B)为假。 |
| != | 检查如果两个操作数的值是否相等,如果值不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是那么条件为真。 | (A> B)为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是那么条件为真。 | (A <B)为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是那么条件为真。 | (A> = B)为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是那么条件为真。 | (A <= B)为真。 |
位运算符
Java定义了位运算符,应用于整数类型(int),长整型(long),短整型(short),字符型(char),和字节型(byte)等类型。
位运算符作用在所有的位上,并且按位运算。假设a = 60,b = 13;它们的二进制格式表示将如下:
A = 0011 1100
B = 0000 1101
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~A = 1100 0011
下表列出了位运算符的基本运算,假设整数变量A的值为60和变量B的值为13:
| 操作符 | 描述 | 例子 | |
|---|---|---|---|
| & | 与 | 如果相对应位都是1,则结果为1,否则为0 | (A&B),得到12,即0000 1100 |
| | | 或 | 如果相对应位都是0,则结果为0,否则为1 | (A | B)得到61,即 0011 1101 |
| ^ | 异或 | 如果相对应位值相同,则结果为0,否则为1 | (A ^ B)得到49,即 0011 0001 |
| 〜 | 非 | 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 | (〜A)得到-61,即1100 0011 |
| << | 按位左移运算符。左操作数按位左移右操作数指定的位数。 | A << 2得到240,即 1111 0000 | |
| >> | 按位右移运算符。左操作数按位右移右操作数指定的位数。 | A >> 2得到15即 1111 | |
| >>> | 无符号右移运算符 按位右移补零操作符。左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充。 | A>>>2得到15即 |
左移运算符 (<<)用 0 填充
有符号右移运算符 (>>)用「符号位」的值
无符号右移运算符 (>>>)用 0 填充
逻辑运算符
下表列出了逻辑运算符的基本运算,假设布尔变量A为真,变量B为假
| 操作符 | 描述 | 例子 |
|---|---|---|
| && | 称为逻辑与运算符。当且仅当两个操作数都为真,条件才为真。 | (A && B)为假。 |
| | | | 称为逻辑或操作符。如果任何两个操作数任何一个为真,条件为真。 | (A | | B)为真。 |
| ! | 称为逻辑非运算符。用来反转操作数的逻辑状态。如果条件为true,则逻辑非运算符将得到false。 | !(A && B)为真。 |
短路逻辑运算符
当使用与逻辑运算符时,在两个操作数都为true时,结果才为true,但是当得到第一个操作为false时,其结果就必定是false,这时候就不会再判断第二个操作了。
public class LuoJi{
public static void main(String[] args){
int a = 5;//定义一个变量;
boolean b = (a<4)&&(a++<10);
System.out.println("使用短路逻辑运算符的结果为"+b);
System.out.println("a的结果为"+a);
}
}
运行结果为:
使用短路逻辑运算符的结果为
false
a的结果为5
解析: 该程序使用到了短路逻辑运算符(&&),首先判断 a<4 的结果为 false,则 b 的结果必定是 false,所以不再执行第二个操作 a++<10 的判断,所以 a 的值为 5。
赋值运算符
下面是Java语言支持的赋值运算符:
| 操作符 | 描述 | 例子 |
|---|---|---|
| = | 简单的赋值运算符,将右操作数的值赋给左侧操作数 | C = A + B将把A + B得到的值赋给C |
| + = | 加和赋值操作符,它把左操作数和右操作数相加赋值给左操作数 | C + = A等价于C = C + A |
| – = | 减和赋值操作符,它把左操作数和右操作数相减赋值给左操作数 | C – = A等价于C = C – A |
| * = | 乘和赋值操作符,它把左操作数和右操作数相乘赋值给左操作数 | C * = A等价于C = C * A |
| / = | 除和赋值操作符,它把左操作数和右操作数相除赋值给左操作数 | C / = A等价于C = C / A |
| (%)= | 取模和赋值操作符,它把左操作数和右操作数取模后赋值给左操作数 | C%= A等价于C = C%A |
| << = | 左移位赋值运算符 | C << = 2等价于C = C << 2 |
| >> = | 右移位赋值运算符 | C >> = 2等价于C = C >> 2 |
| &= | 按位与赋值运算符 | C&= 2等价于C = C&2 |
| ^ = | 按位异或赋值操作符 | C ^ = 2等价于C = C ^ 2 |
| | = | 按位或赋值操作符 | C | = 2等价于C = C | 2 |
instanceof 运算符
该运算符用于操作对象实例,检查该对象是否是一个特定类型(类类型或接口类型)。
instanceof运算符使用格式如下:
( Object reference variable ) instanceof (class类 / interface type接口类型)
如果运算符左侧变量所指的对象,是操作符右侧类或接口(class/interface)的一个对象,那么结果为真。
下面是一个例子:
String name = "James";
boolean result = name instanceof String; // 由于 name 是 String 类型,所以返回真
如果被比较的对象兼容于右侧类型,该运算符仍然返回true。
看下面的例子:
class Vehicle {}
public class Car extends Vehicle {
public static void main(String[] args){
Vehicle a = new Car();
boolean result = a instanceof Car;
System.out.println( result);
}
}
以上实例编译运行结果如下:
true
条件运算符(?:)
条件运算符也被称为三元运算符。该运算符有3个操作数,并且需要判断布尔表达式的值。该运算符的主要是决定哪个值应该赋值给变量。
variable x = (expression) ? value1 : value2
如果expression成立则将value1赋值给x,否者赋值value2
实例
public class Test {
public static void main(String[] args){
int a , b;
a = 10;
// 如果 a 等于 1 成立,则设置 b 为 20,否则为 30
b = (a == 1) ? 20 : 30;
System.out.println( "Value of b is : " + b );
// 如果 a 等于 10 成立,则设置 b 为 20,否则为 30
b = (a == 10) ? 20 : 30;
System.out.println( "Value of b is : " + b );
}
}
运算符优先级
当多个运算符出现在一个表达式中,谁先谁后呢?这就涉及到运算符的优先级别的问题。在一个多运算符的表达式中,运算符优先级不同会导致最后得出的结果差别甚大。
例如,(1+3)+(3+2)*2,这个表达式如果按加号最优先计算,答案就是 18,如果按照乘号最优先,答案则是 14。
再如,x = 7 + 3 * 2;这里x得到13,而不是20,因为乘法运算符比加法运算符有较高的优先级,所以先计算3 * 2得到6,然后再加7。
下表中具有最高优先级的运算符在的表的最上面,最低优先级的在表的底部。
| 类别 | 运算符 |
|---|---|
| 分隔符 | . [ ] ( ) , ; |
| 单目运算符 | ++ -- ~ ! |
| 强制类型转换运算符 | (type) |
| 乘法/除法/求余 | * / % |
| 加法/减法 | + - |
| 移位运算符 | << >> >>>> |
| 关系运算符 | < <= > >= instanceof |
| 等价运算符 | == != |
| 按位与 | & |
| 按位异或 | ^ |
| 按位或 | | |
| 逻辑与 | && |
| 逻辑或 | || |
| 三元运算符 | ?: |
| 赋值 | = += -= *= /= %= &= |= ^= <<= >>= |
1.3 流程控制
switch语句
如果 case 语句块中没有 break 语句时,匹配成功后,从当前 case 开始,后续所有 case 的值都会输出。
switch()括号中是普通表达式(byte,short,int,char,String,Enum)。if中是逻辑表达式。
注意if()括号中如果不是逻辑表达式,而是某些赋值表达式如b = flase则不会进入if语句块内,并且b会真的被赋值为 flase
public class Test {
public static void main(String args[]){
int i = 1;
switch(i){
case 0:
System.out.println("0");
case 1:
System.out.println("1");
case 2:
System.out.println("2");
default:
System.out.println("default");
}
}
}
以上代码编译运行结果如下:
1
2
default
在上面的情况中任何后续的语句块中有break后输出会停止,例如上面的例子中如果case 2有break则default不会输出。
switch (month) {
case 1:
case 2:
case 3:
System.out.println(“第一季度”);
break;
case 4:
case 5:
case 6:
System.out.println(“第二季度”);
break;
case 7:
case 8:
case 9:
System.out.println(“第三季度”);
break;
}
注意switch语句中如果命中了一个case并且该case中没有break会执行下面的所有语句块(跳过case判断)
注意do while后面有分号而单独的while语句没有。
do{
//代码语句
} while(布尔表达式);
Java 增强 for 循环
Java5 引入了一种主要用于数组的增强型 for 循环。
Java 增强 for 循环语法格式如下:
for(声明语句 : 表达式) {
//代码句子
}
声明语句:声明新的局部变量,该变量的类型必须和数组元素的类型匹配。其作用域限定在循环语句块,其值与此时数组元素的值相等。
表达式:表达式是要访问的数组名,或者是返回值为数组的方法。
实例
public class Test {
public static void main(String args[]){
int [] numbers = {10, 20, 30, 40, 50};
for(int x : numbers ){
System.out.print( x );
System.out.print(",");
}
System.out.print("\n");
String [] names ={"James", "Larry", "Tom", "Lacy"};
for( String name : names ) {
System.out.print( name );
System.out.print(",");
}
}
}
以上实例编译运行结果如下:
10``,``20``,``30``,``40``,``50``,``James,Larry,Tom,Lacy,
break 关键字
break 主要用在循环语句或者 switch 语句中,用来跳出整个语句块。
break 跳出最里层的循环,并且继续执行该循环下面的语句。
实例
public class Test {
public static void main(String args[]) {
int [] numbers = {10, 20, 30, 40, 50};
for(int x : numbers ) {
// x 等于 30 时跳出循环
if( x == 30 ) {
break;
}
System.out.print( x );
System.out.print("\n");
}
}
}
以上实例编译运行结果如下:
10
20
continue 关键字
continue 适用于任何循环控制结构中。作用是让程序立刻跳转到下一次循环的迭代。
在 for 循环中,continue 语句使程序立即跳转到更新语句。
在 while 或者 do…while 循环中,程序立即跳转到布尔表达式的判断语句。
语法
continue 就是循环体中一条简单的语句:
continue;
实例
public class Test {
public static void main(String args[]) {
int [] numbers = {10, 20, 30, 40, 50};
for(int x : numbers ) {
if( x == 30 ) {
continue;
}
System.out.print( x );
System.out.print("\n");
}
}
}
以上实例编译运行结果如下:
10
20
40
50
1.4 数组
一维数组
array代表数组变量(数组对象),Arrays是一个工具类(utility class),包含操作数组的静态方法,newLength是一个数值,表示拷贝出的新数组的长度(新数组也可以使用原本的数组变量),排序是从小到大。
| 功能 | 返回 | 示例 |
|---|---|---|
| 打印 | 字符串 | Arrays.toString(array) |
| 比较 | 布尔值 | Arrays.equals(array1, array2) |
| 排序 | Arrays.sort(array) | |
| 复制 | 新数组 | Arrays.copyOf(array, newLength) |
二维数组
- 声明二维数组javatype[][] arrayName;
- 初始化二维数组
- 静态初始化:
arrayName = new type[][]{ {...}, {...}, ... };- 若在声明时直接进行初始化,则可以省略
new type[][]。
- 若在声明时直接进行初始化,则可以省略
- 动态初始化:
arrayName = new type[outerLength][innerLength];
- 静态初始化:
- 访问二维数组
- 访问元素:
arrayName[outerIndex][innerIndex] - 访问长度:
arrayName.length,arrayName[outerIndex].length
- 访问元素:
[ [11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35] ]
Arrays工具类
deepToString
Arrays.deepToString() 是专门用于多维数组的深度转换方法,它能够递归地将多维数组转换为可读的字符串表示形式。
与 Arrays.toString() 的区别
| 方法 | 适用场景 | 对二维数组的输出效果 |
|---|---|---|
Arrays.toString() | 一维数组 | 输出数组的哈希码,如 [[I@1b6d3586, [I@4554617c] |
Arrays.deepToString() | 多维数组 | 输出实际的数组内容,如 [[1, 2], [3, 4]] |
实际运用示例
import java.util.Arrays;
public class DeepToStringExample {
public static void main(String[] args) {
// 定义一个二维数组
int[][] twoDArray = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
// 使用 Arrays.toString() - 不适用于二维数组
System.out.println("使用 toString(): " + Arrays.toString(twoDArray));
// 输出: [[I@1b6d3586, [I@4554617c, [I@74a14482] (无意义的内存地址)
// 使用 Arrays.deepToString() - 适用于二维数组
System.out.println("使用 deepToString(): " + Arrays.deepToString(twoDArray));
// 输出: [[1, 2, 3], [4, 5, 6], [7, 8, 9]] (清晰的数组内容)
// 三维数组示例
int[][][] threeDArray = {
{{1, 2}, {3, 4}},
{{5, 6}, {7, 8}}
};
System.out.println("三维数组: " + Arrays.deepToString(threeDArray));
// 输出: [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]
// 不规则二维数组
String[][] irregularArray = {
{"Java", "Python"},
{"C++"},
{"JavaScript", "TypeScript", "Go"}
};
System.out.println("不规则数组: " + Arrays.deepToString(irregularArray));
// 输出: [[Java, Python], [C++], [JavaScript, TypeScript, Go]]
}
}
主要特点与使用场景
- 递归处理:能够处理任意维度的数组
- 自动格式化:输出格式清晰易读,包含适当的分隔符和缩进
- 处理null值:能够正确处理数组中的null元素
- 适用所有类型:支持基本类型和对象类型的多维数组
- 调试时快速查看多维数组内容
- 日志记录多维数组数据
- 单元测试中比较预期结果和实际结果
数组的可变参数使用
- 在定义方法时,可以声明数量不确定的参数,这样的参数叫可变的参数;
- 一个方法最多声明一个可变参数,并且该参数必须位于参数列表的末尾;
- 可变参数的本质是一个数组,调用时可以分开传入多个值,也可以直接传入一个数组。
写法如下所示,完全可以当成一个数组
public static int sum(int... nums){
for(int num : nums){
...
}
}
1.5 方法
方法的概念
在某些语言中叫函数,它是完成特定任务的独立代码单元。
方法的作用
1.让代码易于复用,避免编写重复的代码,提高编程的效率;
2.让程序更加模块化,从而提高程序的可读性,便于后期的维护。
方法定义
语法
修饰符 返回值 类型 方法名(参数列表) { 方法体}
示例
public static int sum(int m, int n) {
return m + n;
}
1.若没有参数,则参数列表为空即可;
2.return代表方法结束,并返回数据给调用者;
3.若没有返回值,则声明类型为void,此时无需return。
方法参数传递
基本类型参数,传递的是基本类型值的副本,在方法内修改参数不会影响传入的原始变量
引用类型参数,传递的是对象引用的副本,同上
可变参数
什么是可变参数
1.在定义方法时,可以声明数量不确定的参数,这样的参数叫可变的参数;
2.一个方法最多声明一个可变参数,并且该参数必须位于参数列表的末尾;
3.可变参数的本质是一个数组,调用时可以分开传入多个值,也可以直接传入一个数组。 如何声明可变参数
修饰符 返回值 类型 方法名(类型参数1, 类型参数2, …, 类型… 参数N) { }
public static void main(String[] args) {
System.out.println(sum());
System.out.println(sum(1));
System.out.println(sum(1, 2));
System.out.println(sum(1, 2, 3));
System.out.println(sum(new int[]{1, 2, 3, 4, 5}));
}
public static int sum(int... nums) {
int s = 0;
for (int num : nums) {
s += num;
}
return s;
}
方法重载
在同一个类里,定义多个名称相同、参数列表不同的方法,叫做方法重载。
重载定义多个同名的方法(仅参数不同,包括数量类型和排序,不包括参数所定义的名字)
方法重载的作用
对于调用者而言,多个重载的方法就像是一个方法,便于记忆、便于调用。
方法递归
方法调用自身称为方法递归
什么是方法递归
1.一个方法调用它自身,被称为方法递归;
2.递归是一种隐式的循环,它会重复执行某段代码,却无需循环控制。
方法递归的作用
递归为某些编程问题提供了最简单的解决方案;
注意,一些递归算法会快速消耗大量的CPU及内存资源,并且递归不方便理解和阅读!
2. 面向对象编程
2.1 如何描述对象
- 属性
- 对象的静态特征;
- 用变量来描述,这样的变量叫成员变量。
- 行为
- 对象的动态特征;
- 用方法来描述,这样的方法叫成员方法。
2.2 JVM内存模型
JVM启动时会向系统申请一块内存, 它将这块内存划分为若干个子区域, 用以存放不同形式的数据
堆、栈、方法区
JVM内存结构存储对象实例存储局部变量、方法调用存储类信息、常量、静态变量堆 Heap栈 Stack方法区 Method Area其他区域 ...
| 内存区域 | 存储内容 | 特点 |
|---|---|---|
| 堆 (Heap) | 对象实例、数组 | 线程共享,GC主要区域 |
| 栈 (Stack) | 局部变量、方法调用栈帧 | 线程私有,后进先出 |
| 方法区 (Method Area) | 类信息、常量、静态变量 | 线程共享,包含运行时常量池 |
| … | 其他内存区域 | 程序计数器、本地方法栈等 |
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ 堆 │ ←→ │ 栈 │ ←→ │ 方法区 │ │ │ │ │ │ │ │ 对象实例数据 │ │ 局部变量引用 │ │ 类元数据信息 │ └─────────────┘ └─────────────┘ └─────────────┘ ↕ ↕ ↕ ┌────────────────────────────────────────────────┐ │ 其他区域 (…) │ └────────────────────────────────────────────────┘
堆(Heap)
◼堆用于存储引用类型的数据;
◼这些数据相互之间是无序的;
◼堆中数据是可以反复使用的;
◼ JVM会定期清理堆中的垃圾数据;
栈(Stack)
◼栈以方法为单元存储数据,这样的单元叫方法栈帧;
◼栈中存放的数据是有序的,遵循着先进后出的规则;
◼方法调用结束后,它占有的方法栈帧将会立刻释放;
方法区(Method Area)
当虚拟机装载某个类型时,它使用类装载器定位相应的class文件,然后读入class文件,并将它传输到虚拟机中(读入内存)。紧接着虚拟机提取其中的类型信息,并将这些信息存储到方法区。
1.这个类型的全限定名;
2.这个类型的直接父类的全限定名;
3.这个类型是类类型还是接口类型;
4.这个类型的访问修饰符;
5.直接接口的全限定名的有序列表。
1.这个类型的常量池;
2.这个类型的字段信息;
3.这个类型的方法信息;
4.除了常量以外的所有静态变量;
5….
方法区 Method Area堆 Heap栈 StackClass信息
---------
类型信息
方法定义
静态变量对象内存块
---------
地址
实例数据
实例数据引用变量obj
2.3 面向对象的三大特征
- 封装
- 隐藏实现细节,再提供特定的方法访问对象内部的信息,可以提高程序的安全性;
- 继承
- 继承于某一个类,就可以直接获得这个类的属性和方法,可以提高程序的复用性;
- 多态
- 程序运行时,在需要父类的地方均可以传入子类的对象,可以提高程序的扩展性。
封装
访问修饰符
private, protected, public
访问级别:
private-> default -> protected -> public
封装实现方式
1.使用private修饰成员变量,避免它被直接访问;
2.为该成员变量增加赋值、取值方法,使用public修饰这两个方法;
3.在这两个方法中,可以增加任意的数据处理逻辑
继承
extends关键字
- Java采用extends关键字实现继承,实现继承的类叫子类,被继承的类叫父类;
- 任何类都只能有一个直接的父类,和无数个间接的父类,多个类可以继承于同一个父类;
- 若一个类没有显示指定父类,则这个类默认继承于
java.lang.Object;
另外,从父类角度看,父类派生了子类,但从子类角度看,是子类扩展extends了父类。
子类可以继承父类的公有和保护(protected)属性和方法,但不能继承私有(private)属性和方法。
this关键字
含义 :this关键字用于指代当前对象。
用法 :
1.调用当前对象的构造方法;
2.调用当前对象的成员变量;
3.调用当前对象的成员方法
this究竟指代了谁
this指代正在调用方法的那个对象:
1.在构造方法中,this指代正在初始化的对象;
2.在成员方法中,this指代调用该方法的对象。
this是可以省略的
1.Java允许对象的一个成员直接调用另一个成员,这实际上是省略了this;
2.当成员的名称存在冲突,会导致语法产生歧义时,就不能省略this关键字
super关键字
应用
- 通过 super 关键字,调用父类的成员变量;
- 通过 super 关键字,调用父类的成员方法;
- 通过 super 关键字,调用父类的构造方法。
补充说明
- super指代当前对象,用于调用该对象在父类中的成员;
- 通过super调用构造方法时,并不会创建一个新的对象;
- 父类构造方法会在子类构造方法之前调用,并且总会被调用一次。
package com.nowcoder.part20;
public class Truck extends Vehicle {
int maxSpeed = 600;
public Truck(){
super();// 必须在第一行,super()无参的父类构造方法构造
System.out.println("Init Bus.");
}
}
注意上面的super();是会被隐含调用的,即父类的构造器在子类的构造时一定会默认构造无参数的super();,并且在子类之前,如果父类没有无参构造器,仅有有参的,子类构造方法会编译不通过
super()与this()不能同时存在于同一个构造方法中(调用this()方法时也会调用super() ,相当于同时调用了两次super() 方法, 父类被初始化了两次, 这是不被允许的)
super关键字可以调用父类的成员方法
super关键字可以调用父类的构造方法
方法重写
- 什么是重写
- 在子类中,定义与父类同名的方法,用来覆盖父类中这个方法的逻辑,叫做重写。
- 重写的规范
- 子类方法的名称、参数列表与父类相同;
- 子类方法的返回类型与父类相同或更小;
- 子类方法声明的异常与父类相同或更小;
- 子类方法的访问权限与父类相同或更大。
重载与重写对比
- 名称
- 重载英文是overload,重写英文是override。
- 作用
- 重载发生在同一个类的多个同名方法之间,让代码便于调用;
- 重写发生在子类与其父类的同名方法之间,让代码易于复用。
父类与子类之间也存在重载,即在子类中定义出与父类名称相同、参数列表不同的方法。
| 特性 | 方法重载 (Overload) | 方法重写 (Override) |
|---|---|---|
| 发生位置 | 同一个类中 | 父子类之间 |
| 参数列表 | 必须不同 | 必须相同 |
| 返回类型 | 可以不同 | 必须相同(或协变) |
| 访问权限 | 可以不同 | 不能更严格 |
| 异常 | 可以不同 | 不能抛出更宽泛的异常 |
| 多态类型 | 编译时多态 | 运行时多态 |
多态
1.多态的概念 :在程序运行时,相同类型的变量可以呈现出不同的行为特征,这就是多态!
2.多态的作用:提高程序的扩展性!
3.多态的规范:在编写Java代码时,我们只能调用声明变量时所用的类型中包含的成员变量与方法!
优化方案
class Driver {
void drive (Vehicle vehicle) { ... }
}
调用时,可以传入Vehicle类型的对象,也可以传入Vehicle的子类型的对象!
1.运行时,实际传入的对象,可以是声明的类型,也可以是其子类;
2.编译时,只能调用声明的类型的成员,不能调用其子类型的成员;
3.声明的类型也叫编译时类型,运行时传入的类型也叫运行时类型;
对象的类型转换
1.强制类型转换
语法是: (类型) 变量;
只能在具有继承关系的两个类型之间进行,若试图将父类型对象转换为子类型,则这个对象必须实际上是子类实例才行。
2.instanceof 运算符 语法是 : 变量 instanceof 类型
含义:判断变量是否符合后面的类型,或者符合后面的类型的子类、实现类。
注意:instanceof 前面的操作数,要么与后面的类型相同,要么与后面的类型具有继承/实现关系,否则会导致编译报错!
| 方面 | 向上转型(子转父) | 向下转型(父转子) |
|---|---|---|
| 安全性 | ✅ 总是安全 | ⚠️ 需要类型检查,即这个父本来就是子类型 |
| 可见性 | 只能看到父类成员 | 可以看到全部成员 |
| 转换方式 | 自动隐式转换 | 需要强制类型转换 |
父转子例如:
Vehicle vehicle = new Truck();
Truck truck = (Truck) vehicle;
2.4 包(package)
包的作用
包提供了类的多层命名空间,可以解决类的命名冲突、类文件管理等问题。
包的命名规范
包名满足标识符规范即可,建议全用小写字母,以公司域名倒写作为包名。
访问其他包下的类
1.包名.类名
2.import 包名.类名; import 包名.*;
3.默认针对所有源文件 import java.lang.*;
2.5 访问控制详解
成员访问级别
private -> default -> protected -> public
| 修饰符 | 同一个类中 | 同一个包中 | 子类中 | 全局范围内 |
|---|---|---|---|---|
| private | Y | |||
| Y | Y | |||
| protected | Y | Y | Y | |
| public | Y | Y | Y | Y |
类的访问级别
default -> public
| 修饰符 | 同一个包中 | 全局范围内 |
|---|---|---|
| Y | ||
| public | Y | Y |
一个java文件中可以有多个类,但是只能有一个public类,并且必须和文件名同名(可以不存在public类)
2.6 static关键词
static含义
static修饰的成员是类的成员,该成员属于类,不属于单个对象。
可修饰内容
1.Java类中可包含成员变量、方法、构造方法、初始化块、内部类;
2.其中,static可以修饰的是成员变量、方法、初始化块、内部类。
初始化块
初始化块是对构造方法的补充,可用于处理那些与参数无关的、固定的初始化逻辑。
语法
{
. . .
}
执行顺序
1.初始化块总是在构造方法之前执行;(因为编译器会将块中代码编入每一个构造器的开头)
2.多个初始化块之间按书写顺序执行;
3.初始化块与成员变量的初始化,按照代码书写顺序执行。
静态初始化块
1.以static修饰的初始化块叫静态初始化块;
2.静态块属于类,它在类加载的时候被隐式调用一次,之后便再也不会被调用了。
由static修饰的类成员
类成员不能访问实例成员
类变量
1.以static修饰的成员变量叫类变量(静态变量);
2.类变量属于类,它随类的信息存储在方法区(1份),并不随对象存储在堆中;
3.类变量可以通过类名来访问,也可以通过对象名来访问,建议通过类名访问它。
类方法
1.以static修饰的方法叫类方法(静态方法);
2.类方法属于类,可以通过类名访问,也可以通过对象访问,建议通过类名访问。
2.7 final关键词
final关键字可用于修饰类、方法、变量:
final修饰类
final关键字修饰的类不可以被继承;
final修饰方法
final关键字修饰的方法不可以被重写;
final修饰变量
final 关键字修饰的变量,一旦获得了初始值,就不可以被修改
成员变量
类的变量:可在声明变量时指定初始值,也可在静态初始化块中指定初始值;
实例变量:可在声明变量时指定初始值,也可在普通初始化块或构造方法中指定初始值;
局部变量
可在声明变量时指定初始值,也可在后面的代码中指定初始值。final修饰引用类型变量
引用类型变量 , 保存的仅仅是一个引用 ( 地址 ) 。
final只保证这个引用类型变量所引用的地址不会改变,但这个对象的内容可以发送改变。
无论是引用类型的成员变量,或者是引用类型的局部变量,都符合这个规则!
final变量的宏替换原则
满足下述三个条件的变量相当于直接量:
- 使用final关键字修饰;
- 在声明该变量的时候指定了初始值;
- 该初始值可以在编译时被确定下来。
编译时,编译器会把程序中所有用到该变量的地方直接替换成它的值,这个过程叫“宏替换”
2.8 抽象类和抽象方法
抽象类规范
- 使用
abstract关键字修饰的类叫抽象类; - 使用
abstract关键字修饰的方法叫抽象方法,抽象方法不能有方法体; - 抽象类中可以没有抽象方法,但是包含抽象方法的类必须声明为抽象类;
- 若子类是抽象类,可以不实现父类的抽象方法,否则必须实现父类的抽象方法;
- 抽象类允许有构造方法,可以在子类中调用,但是不能调用它来实例化抽象类。
abstract 只能用于修饰类或方法,它不能和 final 同时使用!
模板模式
public abstract class Vehicle {
public abstract void startup();
public void speedup() { ... }
public void stop() { ... }
public void run() { startup(); speedup(); stop(); }
}
模板模式:抽象类作为子类的通用模板,子类在抽象类的基础上进行扩展、改造,但子类在总体上会保留抽象类的行为方式。
2.9 接口
接口是从多个相似的类中抽象出来的规范,体现了规范和实现分离的设计哲学:
接口不提供任何实现,它不能包含普通方法,接口内部定义的所有的方法都是抽象方法!
Java 8 对接口进行了改进,允许在接口中定义默认方法和静态方法,这两类方法可以提供方法实现!
接口定义
语法
[修饰符] interface 接口名 extends 父接口1, 父接口2, ... { }
说明
- 接口名必须符合标识符规范;
- 修饰符可以是
public,也可以省略,省略时该接口是包访问级别; - 一个接口可以有多个直接父接口,但接口只能继承于接口,不能继承于类。
接口成员
接口中可以定义成员变量、成员方法(抽象方法、默认方法、静态方法):
- 接口中所有的成员都是
public访问权限,而public修饰符可以省略; - 接口中的成员变量都是静态常量,而
static final修饰符可以省略; - 接口中的普通的成员方法必须是抽象的,而
abstract修饰符可以省略; - 接口中的默认方法必须使用
default修饰,静态方法必须使用static修饰,均不能省略。
接口中不能包含构造方法和初始化块(static{}), 只能包含静态常量、抽象方法、默认方法、静态方法!
类实现(一些)接口
语法
[修饰符] class 类名 extends 父类 implements 接口1, 接口2, ... { }
说明
- 一个类可以实现一个或多个接口,使用
implements关键字; - 实现与继承类似,可以获得被实现接口里定义的常量、方法;
- 如果这个类不是抽象类,那么它就必须实现这些接口里所定义的全部的抽象方法!
示例
public interface C extends A, B {
public static final int SIZE = 10;
public abstract void sayGoodbye();
public default int max(int x, int y) { ... }
public static int min(int x, int y) { ... }
public class X implements A, B { ... }
public class Y implements C { ... }
}
注意上图中static方法需要用接口名来调用,而default方法需要使用实现该接口的类名来调用(从JAVA8开始有static和default方法),没有删除线的修饰符不能省略,有删除线的为默认就带
| 方法类型 | 调用方式 | 示例 |
|---|---|---|
abstract | 通过实现类实例 | obj.abstractMethod() |
static | 通过接口名 | InterfaceName.staticMethod() |
default | 通过实现类实例 | obj.defaultMethod() |
注意上面X类需要实现接口A和B的所有变量和方法 Y类需要实现接口C的所有变量和方法(包括A和B中的)
类、抽象类、接口都可以实现多态
接口对比抽象类
接口体现的是一种规范,抽象类体现的是一种模板模式的设计
1.接口不能包含构造方法,而抽象类可以包含构造方法;
2.接口不能包含初始化块,而抽象类可以包含初始化块;
3.接口只能定义静态常量,而抽象类可以定义普通成员变量,也可以定义静态常量;
4.接口不能定义普通方法,而抽象类可以定义普通成员方法,也可以定义抽象方法;
5.一个类只能有一个直接父类(包含抽象类),但一个类却可以直接实现多个接口。
2.10 内部类
定义在其他类内部的类叫做内部类,而包含了内部类的类叫做外部类。
作用
1.内部类提供了一种新的封装方式,可以将内部类隐藏在某个外部类的内部;
2.便于访问外部类中的成员,如成员内部类可以直接访问外部类的私有成员;
3.对于那些仅需使用一次的类,采用内部类(匿名内部类)实现会更加方便。
成员内部类
1.定义在外部类内部,与其他成员平级,它是一种新的成员;
2.可以被任意的访问修饰符修饰,一共存在着四种访问级别;
3.被static修饰的成员内部类叫静态内部类,否则叫非静态内部类
非静态内部类
1.非静态内部类中不可以定义任何静态成员;
2.非静态内部类可以访问外部类的实例变量;
3.外部类的静态初始化块、静态方法不能访问非静态内部类;
4.同名的变量可以使用“this.”、“外部类.this.”进行区分;
5.在外部类的外部,也可以实例化非静态内部类,语法如下:
外部类.内部类 变量名 = 外部类实例.new 内部类构造方法( ) ;
即想要创建非静态内部类实例必须先创建外部类实例,而静态内部类则不用
静态内部类(使用更多)
1.静态内部类可以包含静态成员,也可以包含非静态成员;
2.静态内部类不能访问外部类的实例成员,只能访问它的静态成员;
3.外部类的所有方法、初始化块都能访问**其内部定义的静态内部类;
4.在外部类的外部,也可以实例化静态内部类,语法如下:
外部类.内部类 变量名 = new 外部类.内部类构造方法( ) ;
| 访问类型 | 静态方法中 | 实例方法中 |
|---|---|---|
| 实例成员 | ❌ 不能直接访问 | ✅ 可以直接访问 |
| 静态成员 | ✅ 可以直接访问 | ✅ 可以直接访问 |
| 其他实例方法 | ❌ 不能直接调用 | ✅ 可以直接调用 |
| 其他静态方法 | ✅ 可以直接调用 | ✅ 可以直接调用 |
局部内部类
在方法内定义的内部类叫做局部内部类,它仅仅在这个方法内部有效。 不能加访问修饰符,在方法中先定义再实例化。
匿名内部类
1.通常定义在方法调用之时,它没有类名,适合创建只需要使用一次的类。
2.创建匿名内部类之时,会立刻得到这个类的一个实例;
3.匿名内部类在创建时,必须继承一个父类或者实现一个接口。
new 父类构造器(参数列表){// 往往父类是抽象的,有抽象方法,在其中实现其抽象方法
. . .
}
或者
new 待实现的接口(){//写接口抽象方法的实现
. . .
}
例如:
类.方法(参数类型 参数名 , … , new 接口名(){ 待实现的方法 } ); 注意{}位置
2.11 枚举类
有时候一组数据是有限且固定的,比如性别、季节、方向等。
可以定义静态常量来表示这些数据,也可以定义枚举类来表示这些数据。
因为静态常量来表示这些数据有时候不安全,或者说可读性差,可以拿来干别的事情,因此有枚举类。
枚举类的规范
1.枚举类是特殊的类,通过enum关键字进行定义;
2.枚举类可以定义成员变量、成员方法、构造方法,也可以实现接口;
3.枚举类默认继承于java.lang.Enum类,并且不能继承于其他父类;
4.非抽象的枚举类默认使用final修饰,所以枚举类不能派生出子类;
5.枚举类的构造方法默认使用private修饰,并且只能使用private修饰;
6.枚举类的所有实例必须在类中第一行显示列出,它们默认是public static final的。
enum Gender {MALE,FEMALE;}
//其中MALE和FEMALE是构造了两个实例,可以看成是new MALE(),此处使用的是无参构造器。类型是Gender。
enum Gender {
MALE("男"),FEMALE("女");//逗号隔开
private String name;
Gender (String name){
this.name = name;
}
public String getName(){
return this.name;
}
}
//枚举类实现接口
enum Gender implements Printer {
MALE (){
@Override
public void print() { ...}
},
FEMALE() {
@Override
public void print() { ... }
};
}
抽象的枚举类
1.可以在枚举类中定义抽象方法,此时枚举类为抽象类,但不能用abstract修饰该类;
2.枚举类需要显示创建枚举值,所以每个枚举值都需要实现抽象方法,否则会编译报错。
enum Gender {
MALE (){ public void print(} { ... } },//每个枚举值都需要实现抽象方法
FEMALE() { public void print() { .. } };//每个枚举值都需要实现抽象方法
public abstract void print();//抽象方法
}
枚举类的遍历
类名.values()可以返回所有的值,例子:
for(Season value : Season.values()){
System.out.println(value);
}
按行打印出所有的实例名。
3. 高级特性
3.1 引用类型数组
1.Type[] arr = new Type[]{ …};
2.Type[] arr = new Type[length];
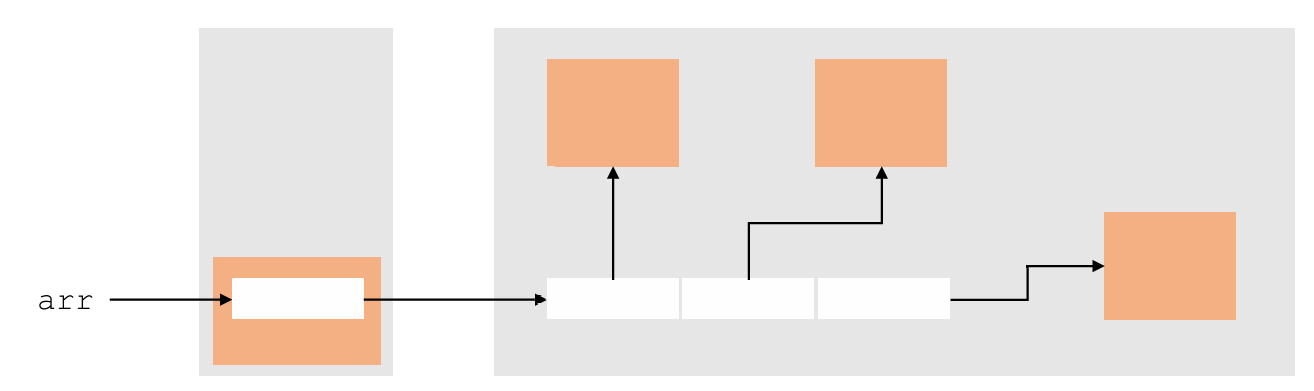
//静态初始化
Car[] cars = {
new Car("奔驰"),
new Car("宝马"),
new Car("奥迪")
};
for (Car car : cars) {
car.run();
}
//动态初始化
Driver[] drivers = new Driver[3];
drivers[0] = new Driver("Tom");
drivers[1] = new Driver("John");
drivers[2] = new Driver("Tony");
for (Driver driver : drivers) {
driver.introduce();
}
3.2垃圾回收
当程序创建引用类型数据时,JVM会在堆内存中为之分配一块内存区。
当这份数据不再被任何变量引用时,它就成了垃圾,对应的内存区就等待垃圾回收器的回收!
针对堆内存!
1.垃圾回收器负责回收堆内存中的空间;
2.程序无法精确的控制垃圾回收的时机;
3.当数据永久的失去引用后,垃圾回收器会在合适的时候回收它的内存区。
finalize方法
定义在java.lang.Object类中:
protected void finalize() throws Throwable { }
1.用于清理对象占用的资源;
2.垃圾回收器在回收某对象的内存之前,会先调用它的finalize方法;
3.针对某一个对象,垃圾回收器最多只会调用它的finalize方法一次。
注意:
1.不要主动调用finalize方法;
2.finalize方法何时调用,是否调用是不确定的!
内存状态
可达状态
若对象至少被一个变量引用,则该对象处于可达状态;
可恢复状态
若对象不再被任何变量引用,它就进入了可恢复状态;
此时垃圾回收器准备回收它的内存,并在回收前调用它的finalize方法;
不可达状态
若在调用finalize法后,对象依然未被引用,它就进入了不可达状态;
只有对象进入了不可达状态,垃圾回收器才会回收该对象占据的内存空间!
失去引用重获引用彻底失去引用切换回收创建之后
可达状态可恢复状态不可达状态垃圾回收
强制垃圾回收
1.System.gc();
2.Runtime.getRuntime().gc();
通知垃圾回收器进行垃圾回收,但是是否回收以及回收时机依然由垃圾回收器决定!
4. Java API
Application Programming Interface,应用程序接口;
Java APT (JavaSE)
4.1 常用api包
| 包 | 描述 |
|---|---|
| java.lang | 提供Java程序设计所需的最基础的类; |
| java.util | 提供集合、字符串解析、随机数生成等常用的工具类; |
| java.text | 提供处理数字、文字、日期等信息的格式的类; |
| java.math | 提供任意精度计算的工具类; |
| java.io | 以数据流、序列化、文件系统的形式提供输入输出操作; |
| java.net | 提供实现联网应用程序的类; |
基础类库
系统相关、用户输入、Object类、包装类、字符串相关、计算相关、日期相关;
核心类库
异常处理、集合、泛型、IO(输入输出)、多线程、网络编程、注解、反射机制。
4.2 文档注释
文档注释规范
1.文档注释以“/*”开始,以“/”结束;
2.提取以public、protected修饰的内容;(私有的无法被外界访问)
3.提取类、接口、构造方法、成员变量、成员方法、内部类之前的注释;
示例
/**
* The String class represents character strings.
* All string literals in Java programs, such as "abc",
* are implemented as instances of this class.
*/
文档注释标记
| 标记 | 位置 | 说明 |
|---|---|---|
| @author | 类、接口 | 指定程序的作者 |
| @version | 类、接口 | 指定程序的版本 |
| @see | 类、接口、构造方法、成员方法、成员变量 | “参见”,用于指定交叉参考的内容 |
| @deprecated | 类、接口、构造方法、成员方法、成员变量 | 不再推荐使用 |
| @param | 构造方法、成员方法 | 方法参数的说明信息 |
| @return | 构造方法、成员方法 | 方法返回值说明信息 |
| @exception | 构造方法、成员方法 | 抛出异常的类型 |
| @throws | 构造方法、成员方法 | 抛出的异常,和 @exception 同义 |
Javadoc命令
规范
javadoc 选项 java源文件/包
示例
javadoc
-d C: \Users \nowcoder\Downloads\mydoc //指定生成文件的存放目录
-windowtitle WINTITLE //网页标题
-doctitle DOCTITLE //多个包的概览页面的标题
-header HEADER //页眉和页脚
-encoding utf-8 -charset utf-8 -author -version *.java
4.3 系统相关类
System类
1.System类代表当前Java程序的运行平台;
2.system类不允许被实例化(构造器private),它所提供的变量和方法全部是静态的;
3.system类提供了代表标准输入、标准输出、错误输出的静态变量;
4.system类提供了访问环境变量、访问系统属性、加载文件、加载动态链接库等方法。
Runtime类
1.Runtime类代表Java程序的运行环境;
2.Runtime类符合单例模式(共有23种设计模式),我们只能通过getRuntime()获得该类型唯一的实例;
3.Runtime类提供了访问JVM相关信息的方法,如获取CPU数量、获取空闲内存数等。
单例模式示例
private Runtime () {} //构造方法
private static final Runtime currentRuntime = new Runtime () ;
public static Runtime getRuntime() { return currentRuntime; }
4.4 用户输入
main()的参数
public static void main(String[] args) {}
命令:java 字节码文件名 字符串1 字符串2 .….
Scanner类
Scanner是一个文本扫描器,它可以从文件、输入流、字符串中解析出基本类型值和字符串类型值。默认的情况下,它使用空白(空格、Tab、回车)作为多个输入项的分隔符。
1.hasNextXxx():判断是否还有下一个输入项,其中Xxx是代表基本类型的单词,如Int、Long、Double等。hasNext()默认是string。
2.nextXxx():获取下一个输入项,其中Xxx的含义同上。
如果你输入3个字符串,例如I am lihua,由于默认空格是分隔符,会当成3个输入,可以用下面的方法修改分隔符。
scanner.useDelimiter("\n");
或者使用输入一行输入流的方法。
scanner.hasNextLine()
4.5 Object类
常用方法(不包括多线程)
| Modifier and Type | Method | Description |
|---|---|---|
| protected Object | clone() | 返回此对象的克隆副本 |
| boolean | equals(Object obj) | 判断此对象是否与其他对象相等(地址是否相等) |
| Class<?> | getClass() | 返回此对象运行时的类 |
| int | hashCode() | 返回此对象的哈希码值 |
| String | toString() | 返回此对象的字符串的表示形式 |
clone()方法
class Driver implements Cloneable{}一个类想要可以克隆必须有这个接口。
4.6 包装类
1.Java是面向对象的语言,在Java中一切皆对象;
2.八种基本数据类型却例外,不具备“对象”的特性;
3.为解决这个问题,Java为每个基本类型都定义了一个对应的引用类型,它们是基本类型的包装类。
| 基本类型 | 包装类型 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
基本类型和包装类型之间的转换
JDK1.5之前
1.通过包装类提供的构造器,可以将基本类型数据转为包装类型的对象;
2.通过包装类提供的xxxValue()方法,可以获得该对象中包装的数据。
JDK 1.5
1.JDK1.5提供了自动装箱、自动拆箱功能;
2.自动装箱:可以把一个基本类型的数据直接赋值给对应的包装类型;
3.自动拆箱:可以把一个包装类型的对象直接赋值给对应的基本类型。
包装类型的API
1. 字符串转为基本类型(以Integer为例)
静态方法:
public static int parseInt(String s) { ... } // 将字符串转换为int基本类型
构造方法:
public Integer(String s) { ... } // 将字符串转换为Integer对象
注意:Character类中没有定义上述的静态方法和构造方法。
2. 字符串转为包装类型
静态方法:
public static Integer valueOf(String s) { ... } // 将字符串转换为Integer对象
3. 比较两个数据的大小(以Integer为例)
public static int compare(int x, int y) { ... }
// x大于y返回1,等于返回0,小于返回-1
对于字符的比较是返回差几个位置,比如A相对于D小3,会返回-3
对于Boolean是任务true比false大,和数值大小比较是同样结果
4. 进制转换方法
System.out.println(Integer.toBinaryString(10)); // 10进制转2进制字符串,输出:"1010"
System.out.println(Integer.toOctalString(10)); // 10进制转8进制字符串,输出:"12"
System.out.println(Integer.toHexString(10)); // 10进制转16进制字符串,输出:"a"
5. 各包装类型的转换方法汇总
| 基本类型 | parseXxx(String) 方法-字符串转为基本类型 | valueOf(String) 方法-字符串转为包装类型 | 特殊说明 |
|---|---|---|---|
| byte | Byte.parseByte(String) | Byte.valueOf(String) | 支持进制参数 |
| short | Short.parseShort(String) | Short.valueOf(String) | 支持进制参数 |
| int | Integer.parseInt(String) | Integer.valueOf(String) | 支持进制参数 |
| long | Long.parseLong(String) | Long.valueOf(String) | 支持进制参数 |
| float | Float.parseFloat(String) | Float.valueOf(String) | – |
| double | Double.parseDouble(String) | Double.valueOf(String) | – |
| boolean | Boolean.parseBoolean(String) | Boolean.valueOf(String) | 只有”true”返回true(忽略大小写) |
6. 使用示例
// 字符串转int
System.out.println(Integer.valueOf("111111")); // 输出:111111
System.out.println(Integer.parseInt("1234")); // 输出:1234
// 支持进制的转换
System.out.println(Short.valueOf("FF", 16)); // 输出:255
System.out.println(Short.parseShort("FF", 16)); // 输出:255
// Boolean的特殊处理
System.out.println(Boolean.parseBoolean("true")); // 输出:true
System.out.println(Boolean.parseBoolean("TRUE")); // 输出:true
System.out.println(Boolean.parseBoolean("false")); // 输出:false
System.out.println(Boolean.parseBoolean("abc")); // 输出:false
7. 注意事项
- NumberFormatException:当字符串无法转换为对应类型时会抛出此异常
- null值处理:传入null参数会抛出NullPointerException
- 进制范围:支持的进制范围为2-36
- Boolean特殊规则:只有”true”(忽略大小写)返回true,其他字符串都返回false
8.基本类型转为String
| 转换方式 | 示例 | 优点 | 缺点 |
|---|---|---|---|
| String.valueOf() | String.valueOf(100) | 通用性强,代码清晰 | – |
| 包装类toString | Integer.toString(100) | 类型明确,支持进制 | 需要知道具体类型 |
| 字符串拼接 | "" + 100 | 简洁方便 | 性能稍差,可读性一般 |
| 格式化 | String.format("%d", 100) | 支持格式化 | 语法相对复杂 |
8.1 使用String.valueOf()方法
// 所有基本类型都可以使用String.valueOf()转换
String str1 = String.valueOf(100); // int → String
String str2 = String.valueOf(3.14); // double → String
String str3 = String.valueOf(true); // boolean → String
String str4 = String.valueOf('A'); // char → String
String str5 = String.valueOf(100L); // long → String
8.2 使用包装类型的toString()方法
// 使用包装类的静态toString方法
String str1 = Integer.toString(100); // int → String
String str2 = Double.toString(3.14); // double → String
String str3 = Boolean.toString(true); // boolean → String
String str4 = Character.toString('A'); // char → String
// 支持进制的转换(Integer为例)
String binary = Integer.toString(10, 2); // 10转2进制字符串,输出:"1010"
String octal = Integer.toString(10, 8); // 10转8进制字符串,输出:"12"
String hex = Integer.toString(10, 16); // 10转16进制字符串,输出:"a"
8.3 使用包装对象的toString()方法
// 先装箱,再调用toString()
Integer num = 100;
String str = num.toString(); // 输出:"100"
Double d = 3.14;
String str2 = d.toString(); // 输出:"3.14"
8.4 使用字符串拼接(隐式转换)
// 通过字符串拼接自动转换
String str1 = "" + 100; // int → String,输出:"100"
String str2 = "" + 3.14; // double → String,输出:"3.14"
String str3 = "" + true; // boolean → String,输出:"true"
String str4 = "" + 'A'; // char → String,输出:"A"
8.5 进制转换专用方法
// Integer类提供的进制转换方法
System.out.println(Integer.toBinaryString(10)); // 10转2进制,输出:"1010"
System.out.println(Integer.toOctalString(10)); // 10转8进制,输出:"12"
System.out.println(Integer.toHexString(10)); // 10转16进制,输出:"a"
// Long类也有对应方法
System.out.println(Long.toBinaryString(10L)); // 输出:"1010"
System.out.println(Long.toHexString(255L)); // 输出:"ff"
8.6 格式化转换
// 使用String.format()进行格式化转换
String str1 = String.format("%d", 100); // 输出:"100"
String str2 = String.format("%.2f", 3.14159); // 输出:"3.14"
String str3 = String.format("%b", true); // 输出:"true"
String str4 = String.format("%c", 'A'); // 输出:"A"
包装类是不可变的
该类被实例化后,它的实例变量是不可改变的: 1.使用private和final修饰成员变量; 2.提供带参数的构造器,用于初始化上述成员变量; 3.仅提供获取成员变量的方法,不提供修改的方法。 包装类都是final的,但final只意味着类不可以被继承,并不意味着它的实例变量不可改变!
包装类的父类
| 包装类型 | 继承关系 |
|---|---|
| Byte | java.lang.Number |
| Short | java.lang.Number |
| Integer | java.lang.Number |
| Long | java.lang.Number |
| Float | java.lang.Number |
| Double | java.lang.Number |
| Character | java.lang.Object |
| Boolean | java.lang.Object |
Number类的主要方法:
public abstract int intValue()
public abstract long longValue()
public abstract float floatValue()
public abstract double doubleValue()
public byte byteValue() //实现了
public short shortValue()//实现了
包装类的静态常量
1.MAX_VALUE,表示该类型的最大值;
2.MIN_VALUE,表示该类型的最小值;
3.Byte、Short、Integer、Long、Float、Double、Character均定义了上述常量!
4.7 字符串处理
String类
不可变类 String也是不可变类,创建string对象后,其内部的字符序列不能修改; 构造方法 public String(String original) {} 使用string
- length () 用于返回字符串的长度;
- getBytes() 通过默认或指定的字符集,将字符串编码为一个字节数组;
- equals() String重写了该方法,用于比较当前字符串与另一个字符串的内容。
- equalsIgnoreCase 相比上面方法忽略字符串的大小写
String strl = new String( "Hello");
String str2 = new String( "Hello");
System.out.println(strl == str2); //false
System.out.println(strl.equals(str2)); //true
- 常量池中的字符串
- 字符串字面量
"Hello"在编译时就被放入方法区的字符串常量池中 - 这个
"Hello"在常量池中只存在一份
- 字符串字面量
- 堆内存中的对象
new String("Hello")每次执行都会在堆内存中创建一个新的String对象str1和str2分别指向堆中两个不同的String对象- 这两个堆中的String对象都指向常量池中同一个
"Hello" - 字符串常量池 (方法区) ┌─────────────┐ │ “Hello” │ ←──┐ └─────────────┘ │ │ 堆内存 │ ┌─────────────┐ │ │ String对象1 │────┘ │ value → │ └─────────────┘ │ ┌─────────────┐ │ │ String对象2 │────┘ │ value → │ └─────────────┘
String str3 = "Hello World";
String str4 = "Hello World";
System.out.println(str3 ==str4); //true
System.out.println(str3.equals(str4)); //true
对于以上代码,虽然String是引用类型,但是对于常量”Hello World”是存放在方法区的字符串常量池中,只存一份,因此str3和str4都是指向用一地址,所以不管是==还是equals都会返回true。
关键区别:
- 第一种情况(new创建):变量指向堆中不同的对象,但这些对象引用常量池中的同一字符串
- 第二种情况(字面量赋值):变量直接指向常量池中的同一对象
String常用API
| 方法 | 说明 |
|---|---|
boolean matches(String regex) | 判断此字符串是否与指定的正则表达式(regex)匹配 |
char charAt(int index) | 返回指定索引处的字符 |
String substring(int beginIndex, int endIndex) | 从此字符串中截取出一部分子字符串,注意此方法可以只传入第一个参数,endindex这个索引不包含在内,即只会截取从beginIndex开始的endIndex-beginIndex个字符 |
String[] split(String regex) | 以指定的规则将此字符串分割成数组,regex分割标准,如空格什么的 |
String trim() | 删除字符串前导和后置的空格 |
int indexOf(String str) | 返回子串在此字符串首次出现的索引 |
int lastIndexOf(String str) | 返回子串在此字符串最后出现的索引 |
boolean startsWith(String prefix) | 判断此字符串是否以指定的前缀开头 |
boolean endsWith(String suffix) | 判断此字符串是否以指定的后缀结尾 |
String toUpperCase() | 将此字符串中所有的字符大写 |
String toLowerCase() | 将此字符串中所有的字符小写 |
String replaceFirst(String regex, String replacement) | 用指定字符串替换第一个匹配的子串 |
String replaceAll(String regex, String replacement) | 用指定字符串替换所有的匹配的子串 |
注意以上参数中的regex都是指的正则表达式匹配方法
假如indexOf()方法未能找到所指定的子串,那么其返回值为-1
StringBuilder类与StringBuffer类
因String是不可变的,所有改动都是新建了一个字符串,多次改动很占用内存,因此StringBuilder类可以被改变,适合需要多次改变的情况。
1.StringBuilder封装可变的字符串,对象创建后可以通过方法改变其封装的字符序列;
2.StringBuffer(线程安全的)、StringBuilder作用与方法是一样的,区别在于前者是线程安全的;
3.StringBuilder是非线程安全的,性能较好,所以通常优先考虑使用StringBuilder。
常用方法
| 方法 | 说明 |
|---|---|
StringBuilder append(String str) | 将指定字符串追加到此字符序列末尾 |
StringBuilder insert(int offset, String str) | 将指定字符串插入到此字符序列中的指定位置 |
StringBuilder delete(int start, int end) | 从此字符序列中删除一组连续的字符 |
示例
StringBuilder sb = new StringBuilder();、System.out.println(sb.capacity()); //打印容量
sb.append("Hello").append("World,").append("Hello");
System.out.println(sb.toString());
4.8 正则表达式
1.在编写处理字符串程序的时候,经常会有查找符合某些复杂规则的字串的需要;
2.正则表达式就是用于描述这些规则的工具,正则表达式就是记录文本规则的代码;
3.各类编程语言都会提供支持正则表达式的API。
元字符
| 元字符 | 说明 |
|---|---|
. | 匹配除换行符以外的任意字符 |
\d | 匹配数字 |
\s | 匹配任意的空白字符(空格、制表符、回车符、换页符、换行符等) |
\w | 匹配字母或数字或下划线 |
\b | 匹配单词的开始或结束 |
^ | 匹配字符串的开始 |
$ | 匹配字符串的结束 |
字符转义:如果要查找元字符本身,则需使用“\”转义,如“\.”、“\*”、“\\”等。
限定符
| 限定符 | 说明 |
|---|---|
* | 重复零次或多次 |
+ | 重复一次或多次 |
? | 重复零次或一次 |
{n} | 重复n次 |
{n,} | 重复n次或更多次 |
{n,m} | 重复n次到m次 |
字符类
[]用于自定义一个字符集合:
1.[aeiou]匹配任何一个元音字母;
2.[0-9]匹配任何一位数字,与“\d”等价;
3.[0-9a-zA-Z_]匹配字母、数字、下划线之中的任何一个字符,与\w等价。
分支条件
用于分割多个规则,满足任意一个规则即匹配成功:
- 0\d{2}-\d{8}|0\d{3}-\d{7}
- \(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}
子表达式
()用于定义子表达式(分组),可以将其作为一个整体,指定重复次数:
ipv4地址表达式
- (\d{1,3}\.){3}\d{1,3}
- ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
反义
| 反义字符 | 说明 |
|---|---|
\W | 匹配不是字母、数字、下划线的字符 |
\S | 匹配不是空白字符的字符 |
\D | 匹配不是数字的字符 |
\B | 匹配不是单词开头或结束的位置 |
[^x] | 匹配除了x以外的任意字符 |
[^aeiou] | 匹配除了aeiou之外的任意字符 |
注意:前四个反义字符需要大写字母,这与对应的元字符(小写字母)功能相反。
重复模式
1.贪婪模式:对于重复限定符,默认情况下会匹配尽可能多的字符,这叫贪婪模式;
2.懒惰模式:在重复限定符之后加上“?”,表示匹配尽可能少的字符,这叫懒惰模式。
| 限定符 | 说明 |
|---|---|
*? | 重复零次或多次,但尽可能少重复 |
+? | 重复一次或多次,但尽可能少重复 |
?? | 重复零次或一次,但尽可能少重复 |
{n,}? | 重复n次或以上,但尽可能少重复 |
{n,m}? | 重复n次到m次,但尽可能少重复 |
示例
besebesbesbebsdae
正则表达式b.*?e
共找到 5 处匹配: be be be be bsdae
如果不带?则是匹配besebesbesbebsdae
String和正则表达式
| 方法 | 功能说明 |
|---|---|
boolean matches(String regex) | 判断此字符串是否与指定的正则表达式(regex)匹配 |
String[] split(String regex) | 以正则表达式(regex)匹配的内容作为分隔符,将此字符串分割成多个子串 |
String replaceFirst(String regex, String replacement) | 将此字符串中,第一个与正则表达式(regex)匹配的子串替换成目标(replacement) |
String replaceAll(String regex, String replacement) | 将此字符串中,每一个与正则表达式(regex)匹配的子串替换成目标(replacement) |
示例
String paragraph = "How are you!\n" +
"I'm fine, thank you, and you?\n" +
"I'm fine too!";
String paragraphReg ="\\n";
String[] words = paragraph.split(paragraphReg);// split方法返回一个数组
System.out.println(Arrays.toString(words));
System.out.println(words.length);
Pattern和Matcher类
1.Pattern对象是正则表达式编译后在内存中的表示形式;
2.Matcher对象是正则表达式与字符串匹配的结果与状态;
3.Matcher对象通过Pattern对象创建而来,且多个Matcher对象可共享一个Pattern对象。
示例
String reg = "^[a-zA-Z0-9_]+@[a-zA-Z0-9]+\\.[a-zA-Z]{2,3}$";
String str = "user@example.com";
Pattern pattern = Pattern.compile(reg); // 编译邮箱正则
Matcher matcher = pattern.matcher(str); // 对"user@example.com"创建匹配器
boolean b = matcher.matches(); // 返回true,完全匹配
Pattern.compile(reg)– 将字符串正则表达式编译成Pattern对象,提高效率pattern.matcher(str)– 创建匹配器,将正则模式应用到具体字符串matcher.matches()– 执行完全匹配,要求整个字符串都符合正则规则
简化写法:
boolean b = Pattern.matches(reg, str); // 一行完成上述三步骤
这种方式的优势在于可以复用Pattern对象,适合多次匹配相同正则模式的情况。
Matcher类的常用方法
| 方法 | 说明 |
|---|---|
boolean matches() | 判断整个字符串是否与正则表达式匹配 |
boolean find() | 判断目标字符串是否包含与正则表达式匹配的子串 |
boolean find(int start) | 从指定位置开始查找匹配的子串 |
String group() | 返回上一次与正则表达式匹配的子串 |
String group(int group) | 返回指定捕获组匹配的内容 |
int groupCount() | 返回正则表达式中的捕获组数量 |
int start() | 返回上一次匹配子串在目标字符串中的开始位置 |
int start(int group) | 返回指定捕获组匹配内容的开始位置 |
int end() | 返回上一次匹配子串在目标字符串中的结束位置(索引+1) |
int end(int group) | 返回指定捕获组匹配内容的结束位置(索引+1) |
Matcher reset() | 重置匹配器状态 |
Matcher reset(CharSequence input) | 重置匹配器并使用新的输入字符串 |
String replaceAll(String replacement) | 替换所有匹配的子串 |
String replaceFirst(String replacement) | 替换第一个匹配的子串 |
说明: 这些方法通常与 java.util.regex.Pattern 和 Matcher 类一起使用,用于在字符串中进行正则表达式匹配和查找操作。
示例1:用户名验证
// Pattern静态方法
System.out.println(Pattern.matches("^\\w{6,20}$", "nowcoder_2020#")); // false
// Pattern实例方法
Pattern userPattern = Pattern.compile("^\\w{6,20}$");
Matcher userMatcher = userPattern.matcher("nowcoder_2020");
System.out.println(userMatcher.matches()); // true
示例2:手机号提取
String str = "高价回收二手电脑,电话:13812345678,15912345678,18612345678,联系人诸葛先生!";
String reg = "(13[0-9]|14[5|7]|15[0-9]|18[0-9])\\d{8}";
Matcher matcher = Pattern.compile(reg).matcher(str);
while (matcher.find()) {
System.out.println("找到手机号: " + matcher.group());
System.out.println("开始位置: " + matcher.start());
System.out.println("结束位置: " + matcher.end());
}
输出:
找到手机号: 13812345678
开始位置: 8
结束位置: 19
找到手机号: 15912345678
开始位置: 20
结束位置: 31
找到手机号: 18612345678
开始位置: 32
结束位置: 43
示例3:捕获组使用
String text = "John Doe, 25 years old";
String regex = "(\\w+)\\s+(\\w+),\\s+(\\d+)\\s+years\\s+old";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
if (matcher.matches()) {
System.out.println("完整匹配: " + matcher.group(0));
System.out.println("名字: " + matcher.group(1));
System.out.println("姓氏: " + matcher.group(2));
System.out.println("年龄: " + matcher.group(3));
System.out.println("捕获组数量: " + matcher.groupCount());
}
示例4:替换操作
String text = "The price is $10.50 and $20.30";
Pattern pattern = Pattern.compile("\\$\\d+\\.\\d+");
Matcher matcher = pattern.matcher(text);
// 替换所有匹配项
String result1 = matcher.replaceAll("XXX");
System.out.println(result1); // The price is XXX and XXX
// 重置匹配器
matcher.reset();
// 替换第一个匹配项
String result2 = matcher.replaceFirst("XXX");
System.out.println(result2); // The price is XXX and $20.30
注意事项
- 性能优化 – 对于频繁使用的正则表达式,应该编译成Pattern对象复用
- 线程安全 – Pattern对象是线程安全的,但Matcher对象不是
- 状态管理 – Matcher对象在匹配操作后会有状态,需要时使用reset()方法重置
- 异常处理 – 不合法的正则表达式会抛出PatternSyntaxException
4.9 数学计算
Math类
算数运算符用于处理基本的数学运算,而Math类用于处理复杂的数学运算!
1.Math类不能被实例化,它的所有成员都是静态的,直接通过类名来访问;
2.Math类提供了两个静态常量,分别是Math.E(自然对数的基数)和Math.PI(圆周率);
3.Math类提供了对数运算、指数运算、三角函数等一系列支持数学运算的方法。
Random类
Random类专门用于生成一个伪随机数:
1.基于一个“种子”,采用特定的算法计算而来的数字;
2.计算结果作为新的“种子”,用于生成下一个随机数;
3.Random类有2个构造器:
-无参构造器,使用默认的种子,即当前时间的毫秒数;
-有参构造器,使用指定的种子,需要调用者显示的传入long型的整数。
若两个Random对象的种子相同,而且它们的方法调用顺序也相同,那它们就会产生相同的数字序列。例如
Random ran1 = new Random(9);
System.out.println(ran1.nextInt(100));
System.out.println(ran1.nextInt(200));
如果是这样永远输出89和196
Random ran1 = new Random(9);
System.out.println(ran1.nextInt(200));
System.out.println(ran1.nextInt(100));
这样却会和上面不一样,输出189和96,和顺序有关系
BigDecimal类(解决浮点数不准确问题)
BigDecimal类用于精确地表示和计算浮点数!
创建实例
1.BigDecimal(String val),建议优先使用,它的结果是可以预知的;
2.BigDecimal(double val),不推荐使用它,因其参数是一个近似值;
3.BigDecimal.valueOf (double val), 将小数转成字符串再创建实例
若必须使用double型参数创建对象,建议调用这个静态方法来创建实例;
成员方法
add()加、subtract()减、multiply()乘、divide()除、pow()等一系列用于精确运算的方法。
对于divide()除法,如果有除不尽的情况,因为无法精确则会报错,可以使用参数,保留特定的位数,例如
BigDecimal d3 = new BigDecimal( "0.0005");
BigDecimal d4 = new BigDecimal( "0.0003");
d3.divide(d4, MathContext.DECIMAL64)
MathContext.DECIMAL64就是可以保留16位,除去小数点。
4.10 格式化
NumberFormat类
NumberFormat用于实现数值的格式化!
创建实例
1.getCurrencyInstance(),返回默认地区的货币格式器;
2.getNumberInstance(),返回默认地区的数值格式器;
3.getPercentInstance(),返回默认地区的百分数格式器;
上述方法均可传入参数以显示地指定地区,并且只能通过上述方法实例化该类(抽象类)。
成员方法
1.format(),将传入的数值格式化为字符串;
2.parse(),将传入的格式字符串解析成数值。
示例
public static void main(String[] args) throws ParseException {
NumberFormat format;
// 通用数值
format = NumberFormat.getNumberInstance();
System.out.println(format.format(1234567.89));
format = NumberFormat.getNumberInstance(Locale.US);
System.out.println(format.format(1234567.89));
System.out.println(format.parse("1,234,567.89"));
// 货币数值
format = NumberFormat.getCurrencyInstance();
System.out.println(format.format(1234567.89));
format = NumberFormat.getCurrencyInstance(Locale.US);
System.out.println(format.format(1234567.89));
System.out.println(format.parse("$1,234,567.89"));
// 百分比数值
format = NumberFormat.getPercentInstance();
System.out.println(format.format(1234567.89));
format = NumberFormat.getPercentInstance(Locale.US);
System.out.println(format.format(1234567.89));
System.out.println(format.parse("123,456,789%"));
}
Locale.US 是Java中预定义的一个Locale常量,表示美国地区设置。
4.11 日期时间
Date类
Date类用来处理日期和时间,该类的大部分构造器、方法均已过时!
构造方法
1.Date(),创建代表当前时间的Date对象,底层调用system类获取当前时间毫秒数;
2.Date(long date),根据指定的时间毫秒数创建Date对象,参数为时间的毫秒数;
成员方法(目前还可使用)
1.boolean after(Date when),判断该时间是否在指定时间之后;
2.boolean before(Date when),判断该时间是否在指定时间之前;
3.long getTime(),返回该时间的毫秒数;
4.void setTime(long time),以毫秒数的形式,设置该Date对象所代表的时间。
虽然Date类仍可使用,但在现代Java开发中,官方推荐使用Java 8引入的java.time包来替代它。
| 特性对比 | java.util.Date (旧版) | java.time 包 (现代API) |
|---|---|---|
| 线程安全 | 否,实例可变 | 是,所有类均为不可变对象 |
| API设计 | 反直觉(如月份从0开始),设计不佳 | 直观清晰(月份从1开始,星期符合枚举) |
| 时间表示 | 日期与时间混合 | 细分为LocalDate, LocalTime, LocalDateTime等 |
| 时区处理 | 依赖SimpleDateFormat(非线程安全),易混淆 | 明确的ZonedDateTime和ZoneId |
| 格式化 | 使用非线程安全的SimpleDateFormat | 使用线程安全的DateTimeFormatter |
| 官方推荐 | 不推荐在新项目中使用 | 推荐用于所有新项目 |
Calendar类
注意此类也存在过时问题,建议考虑使用 java.time 包中的类
DateFormat类
注意此类也存在过时问题,建议考虑使用 DateTimeFormatter
5. 异常处理
当程序运行出现意外情形时,统会自动生成一个异常对象来通知程序!
1.程序中,可以使用特定的语句捕获异常对象,读取对象中的信息,进而作出处理;
2.程序中,可以使用特定的语句抛出异常对象,将这个异常交给程序的调用者处理;
可以在捕获到异常后,作出尽可能的处理,之后再向外抛出,将剩余的部分,交给程序的调用者处理!(即可以同时进行)
5.1 异常体系
非正常情况
总共分为两类:
错误(Error),Error代表虚拟机相关问题,一般无法处理,也无需处理。
异常(Exception)
异常Exception情况
总共分为两类:
RuntimeException,代表运行时异常,程序可以显示处理这种异常,也可以不处理,而是交给顶层调用者统一处理;
非运行时异常(Checked异常),程序必须显示地处理这种异常,否则在编译阶段会发生错误,导致程序无法通过编译!
5.2 异常处理机制
try catch语句
try {
业务逻辑代码
}catch(Exception e){
异常处理代码
}
1.无论哪行代码发生异常,系统都会生成一个异常对象,这与try…catch…语句没有关系;
2.若程序没有对这个异常做任何处理,则程序在此退出,以前的程序中遇到的异常都是这种情况;
3.创建异常对象后,JVM会寻找可以处理e的catch块,并将异常对象交给这个catch去块处理;
4.上面的catch块的参数是Exception类型,是所有异常的父类,按照多态来看,它能处理所有的异常情况。
访问异常信息
| 方法 | 描述 |
|---|---|
| String getMessage() | 返回该异常的详细消息字符串 |
| StackTraceElement[] getStackTrace() | 返回该异常的跟踪栈信息 |
| void printStackTrace() | 将该异常的跟踪栈信息打印到标准输出设备 |
多个catch
try {
业务逻辑代码
} catch (AException e) {
A异常的处理代码
} catch (BException e) {
B异常的处理代码
} ..
BException都是Exception某个子类
1.创建异常对象后,JVM会寻找可以处理它的catch块, 并将异常对象交给这个catch去块处理;
2.程序应该先处理小异常、再处理大异常,即将处理父类异常的catch块放在处理子类异常的catch块之后。
示例
public static void process2(String[] args) {
try {
int m = Integer.parseInt(args[0]);
int n = Integer.parseInt(args[1]);
System.out.println("m / n = " + (m / n));
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("数组下标越界: " + e.getMessage());
} catch (NumberFormatException e) {
System.out.println("数字格式错误: " + e.getMessage());
} catch (ArithmeticException e) {
System.out.println("数学运算失败: " + e.getMessage());
} catch (Exception e) {
System.out.println("未知异常: ");
e.printStackTrace();
}
}
// NullPointerException 空指针异常
// ClassCastException 类型转换异常
public static void process3(Object obj) {
String str = obj.toString();
Integer num = (Integer) obj;
}
非运行时异常(Checked异常)必须捕获处理
// Checked异常
public static void process4(String fileName) {
try {
FileInputStream fis = new FileInputStream(fileName);
} catch (FileNotFoundException e) {
System.out.println("文件不存在: " + e.getMessage());
} catch (Exception e) {
System.out.println("未知异常: ");
e.printStackTrace();
}
}
回收资源/关闭占用资源
finally块
try {
...
} catch (Exception e) {
...
} finally {
...
}
finally块中代码总是会被执行!
- try是必须的,catch、finally是可选的;
- catch、finally二者之中至少要出现一个;
- finally最多出现一次,它必须位于try或所有的catch之后。
自动关闭资源
Java 7增强了try语句的功能,允许自动关闭资源!
try (
声明、初始化N个资源;
) {
...
} catch (Exception e) {
...
}
在try后面的小括号中声明资源会自动关闭
- try语句会在结束时自动关闭这些资源;
- 该资源的实现类必须实现如下接口之一: AutoCloseable、Closeable。
public static void process1(String fileName) {
FileInputStream fis = null;
try {
fis = new FileInputStream(fileName);
System.out.println("read file ...");
} catch (FileNotFoundException e) {
e.printStackTrace();
return; // return前先执行finally语句
} finally {
try {
System.out.println("close file ...");
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
自动关闭资源
public static void process2(String fileName) {
try (
FileInputStream fis = new FileInputStream(fileName);
) {
System.out.println("read file ...");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
注意事项
public static int process3(String str) {
try {
int i = Integer.parseInt(str);
return i;
} catch (NumberFormatException e) {
e.printStackTrace();
return 0;
} finally {
// 一般不要在这里返回数据或抛出异常,下面的return会覆盖掉正常或者异常中的值
return -1;
}
}
5.3 抛出异常
声明抛出异常 (throws)
throws ExceptionClass1, ExceptionClass2, ...
1.位置要求:throws语句用于标识某方法可能抛出的异常,它必须位于方法签名之后;
参数小括号的后面,大括号的前面
2.作用机制:throws语句声明抛出异常后,程序中就无需使用try语句捕获该异常了;
3.重写规则:在重写时,子类方法声明抛出的异常类型不能比父类方法声明抛出的异常类型大
public static void process1(String[] args)
throws ArrayIndexOutOfBoundsException, NumberFormatException, ArithmeticException {
int m = Integer.parseInt(args[0]);
int n = Integer.parseInt(args[1]);
System.out.println("m / n = " + (m / n));
}
public static void process2(String fileName) throws FileNotFoundException {
FileInputStream fis = new FileInputStream(fileName);
}
抛出异常 (throw)
throw ExceptionInstance;//抛出异常实例
1.主动抛出:throw语句用于在程序中主动抛出一个异常;
2.抛出对象:throw语句抛出的不是异常类型,而是一个异常实例;
3.处理方式:对于主动抛出的异常,也可以采用try块捕获,或者采用throws语句向外抛出。
public static void process3(String fileName) throws FileNotFoundException {
if (fileName == null || fileName.equals("")) {
throw new FileNotFoundException("file can't be null.");
}
}
public static double divide(double m, double n) throws IllegalArgumentException {
if (n == 0.0) {
throw new IllegalArgumentException("n can't be zero.");
}
return m / n;
}
| 特性 | throws | throw |
|---|---|---|
| 作用 | 声明可能抛出的异常类型 | 实际创建并抛出异常实例 |
| 位置 | 方法签名中 | 方法体内 |
| 后面跟的内容 | 异常类名 | 异常对象实例 |
| 数量 | 可声明多个异常类 | 一次只能抛出一个异常实例 |
对字符串判空:if (fileName == null || fileName.equals(“”)) 先判断是否null,不然会导致null.equals()
调用端处理方式
无论是 throws还是 throw都需要处理异常。
// 方式1:使用try-catch捕获处理
try {
process1(args);
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("数组下标越界: " + e.getMessage());
} catch (NumberFormatException e) {
System.out.println("数字格式错误: " + e.getMessage());
} catch (ArithmeticException e) {
System.out.println("数学运算失败: " + e.getMessage());
}
// 方式2:继续向外抛出
public void callerMethod() throws FileNotFoundException {
process2("C:\\work\\2.txt");
}
5.4 自定义异常
异常类定义
1.若定义Checked异常,则继承于Exception; (受检异常)
// 继承于 Exception
class SomeCheckedException extends Exception {
// 构造方法...
}
2.若定义Runtime异常,则继承于RuntimeException; (运行时异常)
// 继承于 RuntimeException
class SomeRuntimeException extends RuntimeException {
// 构造方法...
}
3.自定义的异常类,通常需提供如下构造方法:
public class CustomException extends Exception {
// 无参构造方法
public CustomException() {
super();
}
// 带详细消息的构造方法
public CustomException(String message) {
super(message);
}
// 带详细消息和原因的构造方法
public CustomException(String message, Throwable cause) {
super(message, cause);
}
}
业务逻辑中使用自定义异常
public class ExceptionDemo4 {
public static void main(String[] args) {
try {
String username = inputUsername();
System.out.println("账号创建成功: " + username);
} catch (UsernameException e) {
System.out.println("账号异常: " + e.getMessage());
// 可获取原始异常原因
if (e.getCause() != null) {
System.out.println("根本原因: " + e.getCause().getMessage());
}
}
}
public static String inputUsername() throws UsernameException {
System.out.println("请输入账号:");
try (Scanner scanner = new Scanner(System.in)) {
String username = scanner.nextLine();
// 业务规则验证:账号必须是6-20位字母数字下划线
if (!username.matches("^\\w{6,20}$")) {
throw new UsernameException("账号格式错误! 必须是6-20位字母、数字或下划线");
}
return username;
} catch (RuntimeException e) {
// 包装原始异常,提供更明确的错误信息
throw new UsernameException("输入账号失败!", e);
}
}
}
class UsernameException extends Exception {
public UsernameException() {
super();
}
public UsernameException(String message) {
super(message);
}
public UsernameException(String message, Throwable cause) {
super(message, cause);
}
}
5.5 异常高级特性
异常跟踪栈
1.程序运行时,经常会发生一系列方法调用,从而形成方法调用栈;
2.异常机制会导致异常在这些方法之间传播,而异常传播的顺序与方法的调用相反;
3.异常从发生异常的方法向外传播,首先传给该方法的调用者,再传给上层调用者…
4.最终传到main方法,若依然没有得到处理,则JVM会终止程序,并打印异常跟踪栈信息!
示例,体现了栈的顺序
Exception in thread "main" java.lang.NumberFormatException: For input string: "hello"
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:658)
at java.base/java.lang.Integer.parseInt(Integer.java:776)
at com.nowcoder.chapter3.part36.ExceptionDemo1.process1(ExceptionDemo1.java:24)
at com.nowcoder.chapter3.part36.ExceptionDemo1.main(ExceptionDemo1.java:12)
因此在显示异常时也可以打印栈信息
try {
Integer.parseInt("abc");
} catch (NumberFormatException e) {
System.out.println("整数解析失败!");
e.printStackTrace(); //打印栈信息
// throw e;
}
异常处理的原则
◼不要过度的使用异常
不要用异常处理代替错误处理代码,不要用异常处理代替流程控制语句;
◼不要忽略捕获的异常
对于捕获到的异常,要进行合适的修复,对于不能处理的部分,应该抛出新的异常;
◼不要直接捕获所有的异常
应对不同的异常做出有针对性的处理,而捕获所有的异常,容易压制(丢失)异常;
◼不要使用过于庞大的try代码块
庞大的try块会导致业务过于复杂,不利于分析异常的原因,也不利于程序的阅读及维护!
6. 集合框架
6.1 集合概述
◼集合用于存储数量不等的对象(只能保存对象),集合类也叫容器类;
集合分类
◼集合大致可以分为Set、List、Queue、Map四种体系:
1.Set,代表无序、不可重复的集合;
2.List,代表有序、可以重复的集合;
3.Queue,用于模拟队列这种数据结构;
4.Map,代表着具有映射关系的集合;
◼集合类都位于java.util包下,这些类都是从Collection和Map接口派生而来!
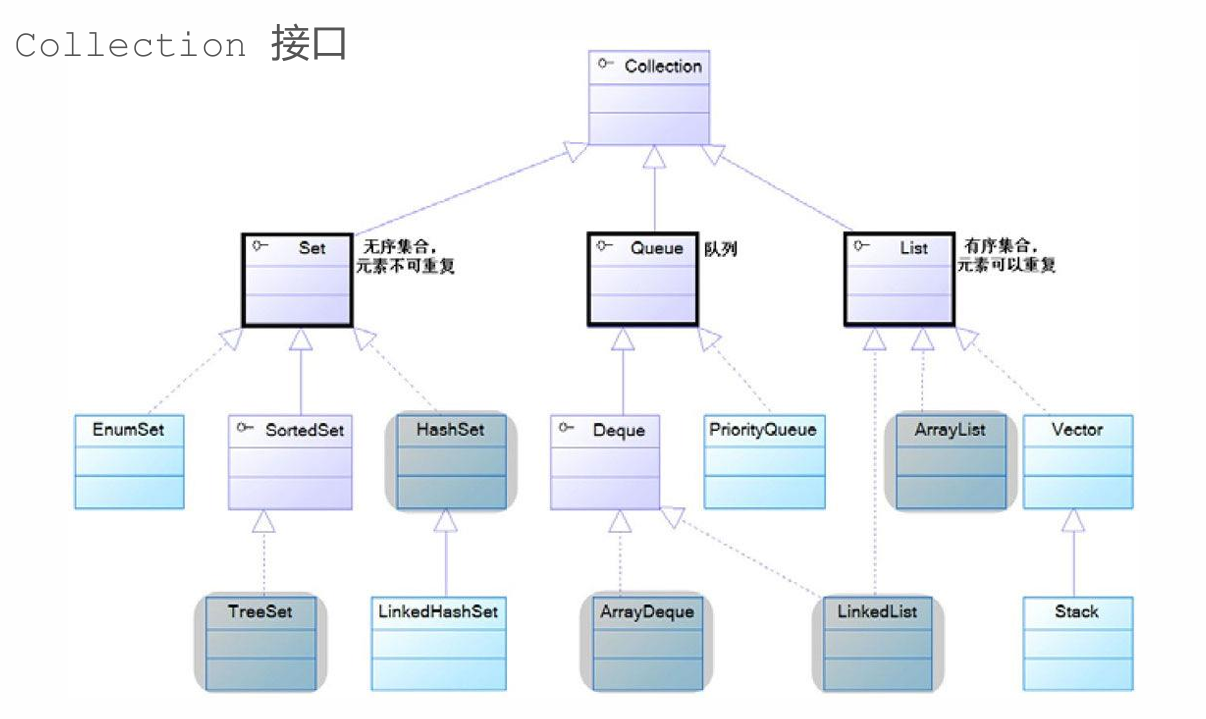
collection接口
类图上面已经给出,不再重复放置。
◼ Collection接口是Set、Queue、List接口的父接口;
◼ Collection接口中定义了这三种集合体系都具备的、通用的方法;
◼ Collection接口的常用方法:
添加元素、删除元素、返回元素个数、遍历集合元素、判断是否包含某元素等。
public class CollectionDemo1 {
private static Date today = new Date();
public static void main(String[] args) {
Collection c = new ArrayList();
c.add(today);
c.add("nowcoder");
c.add(10); // 自动装箱
System.out.println(c); // toString()
System.out.println(Arrays.toString(c.toArray()));
System.out.println(c.size());
System.out.println(c.contains(today));
System.out.println(c.contains("nowcoder"));
System.out.println(c.contains(10));// 自动装箱
c.remove(today);
System.out.println(c);
c.clear();
System.out.println(c);
}
}
6.2 迭代器
Iterator接口(Collection)
◼ Iterator(迭代器)是一个接口,用于遍历Collection中的元素;
◼ Collection接口中的iterator()方法返回Iterator接口的实例;
◼ Iterator主要提供如下几个方法:
boolean hasNext()如何集合还没有迭代完,则返回true;
Object next()返回集合里的下一个元素;
void remove()删除集合里上一次next方法返回的元素。
public class CollectionDemo2 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("唐僧");
c.add("悟空");
c.add("八戒");
c.add("沙僧");
c.add("白龙");
for (Object obj : c) {
System.out.println(obj);
// if (obj.equals("悟空")) {
// c.remove(obj);有问题,因此用下面的iterator
// }
}
Iterator iterator = c.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
if (obj.equals("悟空")) {
// c.remove(obj);
iterator.remove();
}
}
System.out.println(c);
}
}
ListIterator接口(List)
◼ List提供了listIterator()方法,以返回一个ListIterator对象;
◼ ListIterator接口继承于Iterator接口,该接口增加了如下的方法:
1.boolean hasPrevious()判断迭代器指向的元素是否有上一个元素;
2.Object previous()返回该迭代器所指向的元素的上一个元素;
3.void add(Object o)在迭代器所指向的元素位置插入一个元素。
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.ListIterator;
public class ListDemo1 {
public static void main(String[] args) {
List names = new ArrayList();
names.add("Lily");
names.add("Mary");
names.add("John");
names.add("Tony");
names.add("Lisa");
names.add("Mary");
System.out.println(names);
names.add(1, "Lucy");
System.out.println(names);
names.remove(1);
System.out.println(names);
for (int i = 0; i < names.size(); i++) {
System.out.println((i + 1) + ": " + names.get(i));
}
System.out.println(names.subList(1, 4));//大于等于1小于4
System.out.println(names.indexOf("Mary") + ", " + names.lastIndexOf("Mary"));
ListIterator iterator = names.listIterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
System.out.println();
while (iterator.hasPrevious()) {
System.out.print(iterator.previous() + " ");
}
System.out.println();
// 排序
names.sort(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
String s1 = (String) o1;
String s2 = (String) o2;
if (s1 == null && s2 == null) {
return 0;
} else if (s1 == null) {
return -1;
} else if (s2 == null) {
return 1;
} else {
return s1.compareTo(s2);
}
}
});
System.out.println(names);
}
}
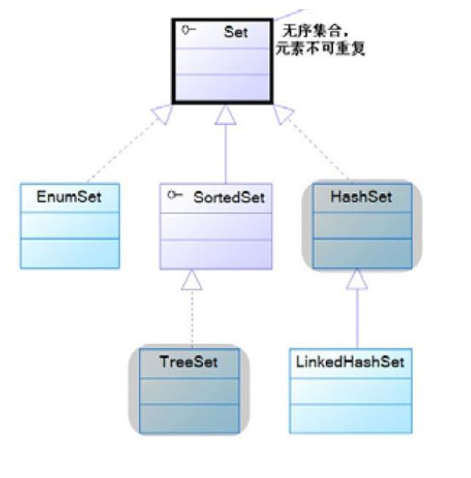
6.3 Set接口
◼ Set集合通常记不住元素的添加顺序;
◼ Set集合不允许包含相同的元素,向Set中加入相同元素时会失败(方法返回false);
◼ Set接口的常用实现类有HaseSet、TreeSet、LinkedHashSet
Set实现类
◼ HashSet不能保证元素的排列顺序;
◼ LinkedHashSet采用链表结构维护元素的顺序;
◼ TreeSet支持两种排序方式,以保证元素的顺序。
- HashSet的性能总比TreeSet好,因为TreeSet需要通过红黑树算法来维护元素的顺序;
- 对于插入、删除操作,LinkedHashSet比HashSet略慢, 这是由维护链表增加的开销,但因为有了链表,所以遍历 时LinkedHashSet更快
HashSet类
HashSet是Set接口的典型实现,它具有以下特点:
1.HashSet不能保证元素的排列顺序;
2.HashSet集合元素的值可以是null;
3.HashSet是非线程安全的,多线程环境下须通过代码来保证其同步。
LinkedHashSet类
LinkedHashSet是HashSet的子类,它具备HashSet的一切特点,同时LinkedHashSet采用链表结构维护了元素的插入顺序!
public class SetDemo1 {
public static void main(String[] args) {
HashSet students = new HashSet();
students.add("唐僧");
students.add("悟空");
students.add("八戒");
students.add("唐僧"); // false
students.add(null);
System.out.println(students);
LinkedHashSet teachers = new LinkedHashSet();
teachers.add("刘备");
teachers.add("关羽");
teachers.add("张飞");
teachers.add("刘备"); // false
teachers.add(null);
System.out.println(teachers);
}
}
TreeSet类
TreeSet可以保证元素的排列顺序,它比HashSet多了一些方法:
1.返回集合中的第一个(最后一个)元素;
2.返回集合中位于指定元素之前(之后)的元素;
3.返回集合中某个限定范围内的元素组成的子集;
自然排序vs定制排序
TreeSet采用红黑树的数据结构来存储元素
支持两种排序方式:自然排序、定制排序。
自然排序
1.添加时,调用元素的compareTo方法比较元素的大小,并按照升序排列元素;
2.添加到TreeSet中的对象必须实现Comparable接口,该接口定义了compareTo方法;
3.Java提供的很多类型均已经实现了Comparable接口,如包装类、String、Date等。
obj1.compareTo(obj2)该方法返回一个int类型的整数,返回0代表对象相等, 返回正数则代表obj1更大,返回负数则代表obj2更大。
定制排序
1.创建TreeSet时,传入Comparator接口的实例;
2.Comparator接口定义了compare方法,用于比较两个对象的大小;
3.TreeSet不再调用compareTo(),转而调用compare()比较大小。
obj1.compare(obj2) 该方法返回一个int类型的整数,返回0代表对象相等, 返回正数则代表obj1更大,返回负数则代表obj2更大。
import java.util.Comparator;
import java.util.TreeSet;
public class SetDemo2 {
public static void main(String[] args) {
TreeSet scores = new TreeSet();
scores.add(83);
scores.add(37);
scores.add(92);
scores.add(54);
scores.add(75);
scores.add(60);
System.out.println(scores);//从小到大排序
System.out.println(scores.first() + " - " + scores.last());//输出37 - 92
System.out.println(scores.lower(60) + " - " + scores.higher(60));//输出54 - 75
System.out.println(scores.headSet(60));//输出[37, 54]
System.out.println(scores.tailSet(60));//输出[60, 75, 83, 92]
// 自然排序
TreeSet names = new TreeSet();
names.add("Lily");
names.add("John");
names.add("Tony");
names.add("Lisa");
names.add("Mary");
System.out.println(names);//按字母列表排序
// 没有实现Comparable接口
// TreeSet objs = new TreeSet();
// objs.add(new Object());
// objs.add(new Object());
// objs.add(new Object());
// 类型不一样,没有可比性.
// TreeSet objs = new TreeSet();
// objs.add("nowcoder");
// objs.add(100);
// 定制排序 匿名内部类实现Comparable接口
TreeSet nums = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Number n1 = (Number) o1;
Number n2 = (Number) o2;
if (n1 == null && n2 == null) {
return 0;
} else if (n1 == null) {
return 1;
} else if (n2 == null) {
return -1;
} else if (n1.doubleValue() > n2.doubleValue()) {
return -1;
} else if (n1.doubleValue() < n2.doubleValue()) {
return 1;
} else {
return 0;
}
}
});
nums.add(null);
nums.add(83.5);
nums.add(37);
nums.add(92.5);
nums.add(54);
nums.add(75);
nums.add(60);
System.out.println(nums);//输出[null,37,54,60,75,83.5,92.5]
}
}
6.4List接口
List代表有序集合,它提供了根据索引来访问集合的方法:
1.将元素插入到集合中指定的索引处;
2.将指定索引处的元素从集合中删除;
3.从集合中返回指定索引处的元素;
4.返回某个元素在集合中的索引值;
5.从集合中,返回起始索引和结束索引之间的元素所组成的子集。
ArrayList类
1.ArrayList是基于数组实现的List接口;
2.ArrayList内部封装了一个长度可变的Object[]数组;
3.默认该数组的初始长度为10,也可以通过构造器参数显示指定其初始长度;
4.每当添加的元素个数超出数组的长度,ArrayList会自动对长度进行扩展。
Arrays.ArrayList(重名的,提及一下)
List Arrays.asList(Object… o)
1.该方法可以将多个对象或一个对象数组转换成一个List集合;
2.实际返回的类型是Arrays的内部类,名字也叫ArrayList;
3.Arrays.ArrayList是一个固定长度的集合,可以遍历,但不能增加、删除!
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ListDemo2 {
public static void main(String[] args) {
// 0, 10, 10 + 10/2,,初始10,后续扩大为原来的1.5倍
ArrayList names = new ArrayList();
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily");
names.add("Lily"); // 11
// Arrays.ArrayList
// int[] nums = {10, 20, 30, 40, 50};//会被当成一个对象
Integer[] nums = {10, 20, 30, 40, 50};
List numList = Arrays.asList(nums);//需要多个对象的数组
System.out.println(numList);
}
}
Vector接口
1.Vector也是基于数组的实现,与ArrayList用法相同;
2.Vector是线程安全的,ArrayList则是非线程安全的;
3.Vector有保证线程安全的开销,所以性能不如ArrayList;
4.Vector的子类Stack,用于模拟栈这种数据结构(LIFO)。
Vector、Stack是古老的集合类,性能很差,不建议使用!
- Collections工具类可以将ArrayList变成线程安全的类;
- 当程序中需要使用栈的数据结构时,推荐使用ArrayDeque。
LinkedList类
◼有序集合
LinkedList采用链表结构实现有序集合;
ArrayList采用数组实现(初始长度10);
◼双端队列
LinkedList采用链表结构实现双端队列;
ArrayDeque采用数组实现(初始长度16); 关键点:数组方式实现与链表方式实现的区别!
数组VS链表
1.数组需要占据连续的内存空间,访问效率高,增删效率低;类似A0 A1 A2 A3 A4
2.链表不必占据连续的内存空间,增删效率高,访问效率低, 它以指针维护元素顺序,即上一个元素会指向下一个元素。
3.LinkedList以双链表结构实现!
6.5Queue接口
Queue基本操作
Queue用于模拟队列,它是一种先进先出(FIFO)的容器。
| 方法 | 返回值类型 | 说明 | 抛出异常或返回特殊值 |
|---|---|---|---|
| 添加元素 | |||
add(Object e) | boolean | 将元素加入队列尾部。如果队列已满,抛出异常。 | IllegalStateException |
offer(Object e) | boolean | 将元素加入队列尾部。如果队列已满,返回特殊值 false。 | true / false |
| 获取头部元素 | |||
element() | Object | 获取队列头部的元素,但不删除。如果队列为空,抛出异常。 | NoSuchElementException |
peek() | Object | 获取队列头部的元素,但不删除。如果队列为空,返回特殊值 null。 | 元素 / null |
| 移除头部元素 | |||
remove() | Object | 获取并移除队列头部的元素。如果队列为空,抛出异常。 | NoSuchElementException |
poll() | Object | 获取并移除队列头部的元素。如果队列为空,返回特殊值 null。 | 元素 / null |
- “抛出异常”组 vs “返回特殊值”组:
add()、element()、remove()在操作失败时(如空队列或满队列)会抛出异常。offer()、peek()、poll()在操作失败时会返回一个特殊值(false或null),更适用于有容量限制或在不确定状态下使用。
- 操作类型:
- 插入:
add()和offer() - 检查(不删除):
element()和peek() - 移除并返回:
remove()和poll()
- 插入:
Queue实现类-PriorityQueue
1.PriorityQueue是一种不标准的队列实现,它不是按照加入的顺序来保存元素,而是按照元素的大小排序来保存元素;
2.Deque接口是Queue的子接口,代表双端队列,它允许你从队列头/尾的任何一 端,来进行入队/出队操作,甚至还支持入栈/出栈的操作;
3.ArrayDeque、LinkedList是Deque接口的实现类,前者采用数组实现双端队列,而后者采用链表结构实现双端队列。
import java.util.ArrayDeque;
import java.util.Queue;
public class QueueDemo1 {
public static void main(String[] args) {
Queue queue = new ArrayDeque();
queue.offer("Mary");
queue.offer("Lily");
queue.offer("Tony");
queue.offer("John");
queue.offer("Lucy");
System.out.println(queue);
// 返回头部(不删),队列为空时返回null.
System.out.println(queue.peek());
System.out.println(queue.peek());
System.out.println(queue);
// 返回头部(删除),队列为空时返回null.
while (queue.size() > 0) {
System.out.println(queue.poll());
}
System.out.println(queue);
}
}
Deque接口
Deque代表双端队列,它允许你从两端来操作队列中的元素,并支持入栈及出栈操作。 Deque在Queue的基础上,增加了两类方法:
◼双端队列方法
boolean offerFirst(Object e),
boolean offerLast(Object e),
Object peekFirst ( ), Object peekLast ( ),
Object pollFirst ( ), Object pollLast ( )
◼栈方法
void push(Object e),
Object pop()、
ArrayDeque类
import java.util.ArrayDeque;
import java.util.Deque;
public class QueueDemo2 {
public static void main(String[] args) {
// 双端队列
Deque queue = new ArrayDeque();
queue.offer("Mary");
queue.offer("Lily");
queue.offer("Tony");
System.out.println(queue);
queue.offerFirst("John");
System.out.println(queue);
queue.offerLast("Lucy"); // == offer()
System.out.println(queue);
System.out.println(queue.peekFirst()); // == peek()
System.out.println(queue.peekLast());
System.out.println(queue);
while (queue.size() > 0) {
// System.out.println(queue.pollLast());
System.out.println(queue.pollFirst()); // == poll()
}
System.out.println(queue);
// 栈
Deque stack = new ArrayDeque();
stack.push("唐僧");
stack.push("悟空");
stack.push("八戒");
stack.push("沙僧");
System.out.println(stack);
while (stack.size() > 0) {
System.out.println(stack.pop());
}
System.out.println(stack);
}
}
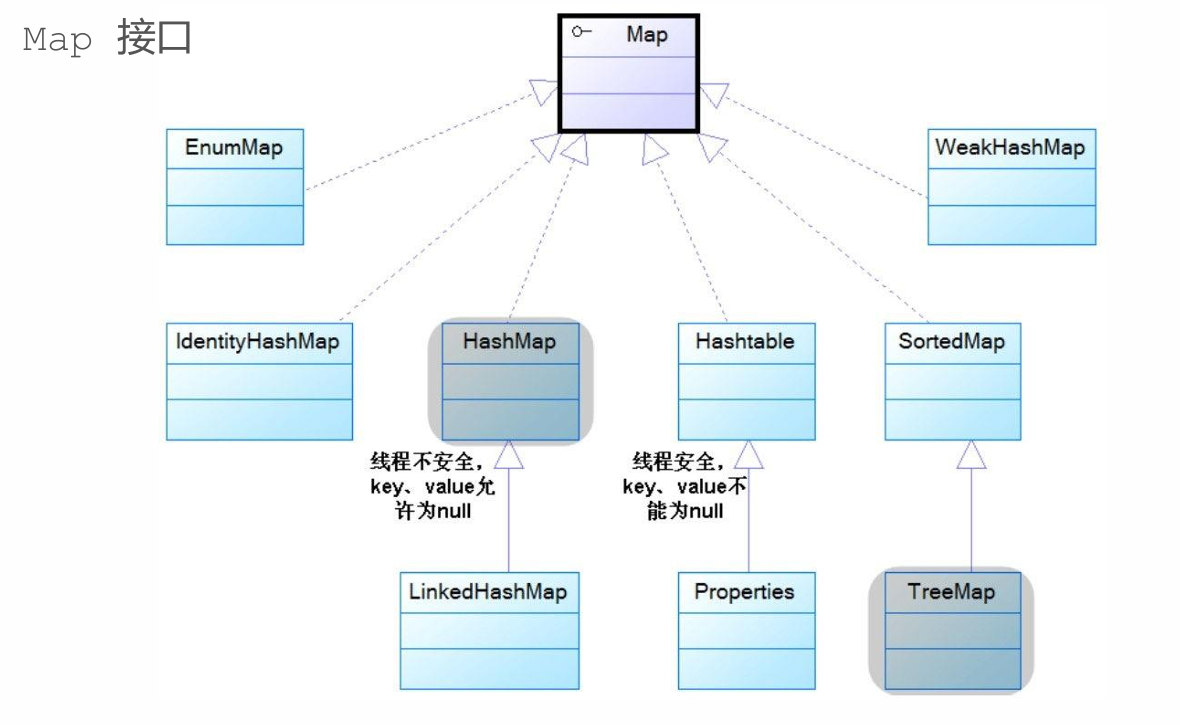
6.6Map接口
◼ Map用于保存具有映射关系的数据(key-value/键-值);
◼ key和value之间存在单向一对一关系,通过指定的key,总能找到确定的value;
◼ Map的key不允许重复,同一个Map的任何两个key通过equals比较总返回false。
注意其实set是由map忽视value而形成的,调用的是map的实现接口。
Map实现类
◼ HashMap是Map接口的典型实现;
◼ LinkedHashMap采用链表维护键值对的顺序;
◼ Hashtable是古老的Map实现类(线程安全);
◼ Propertie常被用于处理属性文件;
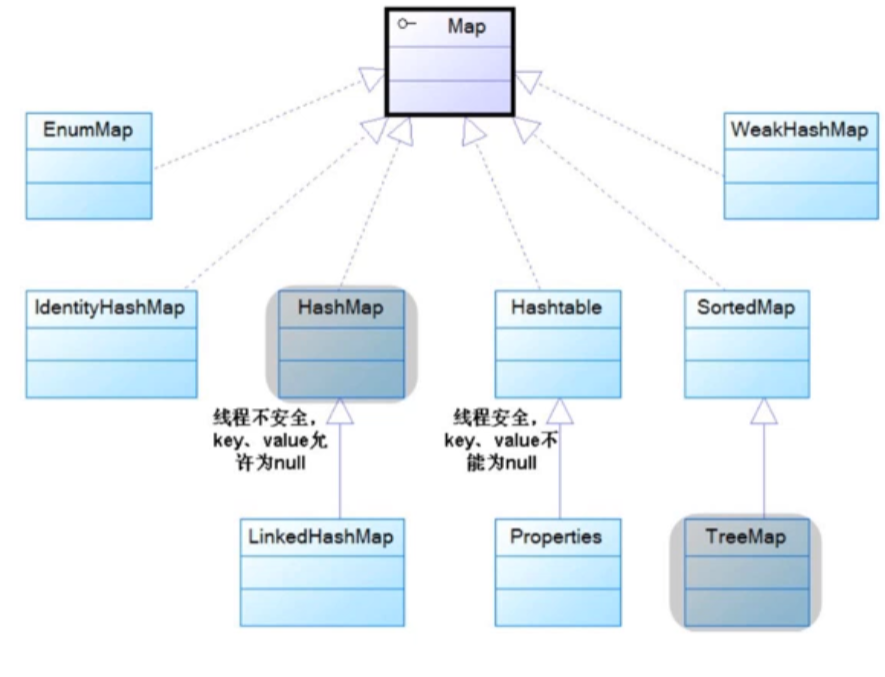
◼ SortedMap是Map的子接口(两种排序方式);
◼ TreeMap采用红黑树结构实现了SortedMap;//注意下面的图按这里,SortedMap是接口
- EnumMap专门用于处理枚举类型的映射关系;
- IdentityHashMap与HashMap类似,但该类以严格相等的方式(key1==key2)认定key的相等;
- WeakHashMap与HashMap类似,但该类的key采用的是弱引用,而HashMap的key采用的是强引用。
import java.util.HashMap;
import java.util.Map;
public class MapDemo1 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("John", 70);
map.put("Lily", 80);
map.put("Tony", 90);
System.out.println(map);
// value可以重复
map.put("Mary", 80);
System.out.println(map);
// key重复会导致覆盖
map.put("Lily", 85);
System.out.println(map);
map.remove("Mary");//删除key
System.out.println(map);
System.out.println(map.get("Tony"));//获取值
System.out.println(map.containsKey("Lily"));//查看是否有这个key
System.out.println(map.containsValue(85));//查看是否有这个值
// entrySet()
for (Object entry : map.entrySet()) {
Map.Entry e = (Map.Entry) entry;
System.out.println(e.getKey() + ": " + e.getValue());//打印key和value
}
// keySet()
for (Object key : map.keySet()) {
System.out.println(key + ": " + map.get(key));//打印key和value,更通用吧
}
// values()
for (Object value : map.values()) {
System.out.println(value);//仅打印value
}
}
}
HashMap
◼ HashMap
1.HashMap是非线程安全的,其性能高于Hashtable;
2.HashMap允许使用null作为key/value,而Hashtable不允许存入null。
◼ LinkedHashMap
1.LinkedHashMap采用双向链表维护键值对的顺序;
2.相对于HashMap,LinkedHashMap在迭代时性能略高,在插入时性能略低。
import java.util.HashMap;
import java.util.Hashtable;
import java.util.LinkedHashMap;
import java.util.Map;
public class MapDemo2 {
public static void main(String[] args) {
Map map = null;
// map = new Hashtable();
// map.put("Tony", null);//不可以
// map.put(null, null);//不可以
map = new HashMap();
map.put("Lily", null);
map.put("John", null);
map.put("Mary", null);
map.put(null, null);
map.put(null, null);
System.out.println(map);
for (Object key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
map = new LinkedHashMap();
map.put("语文", 50);
map.put("数学", 65);
map.put("英语", 70);
map.put("物理", 75);
map.put("化学", 80);
System.out.println(map);
for (Object key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
}
}
Properties
◼属性文件 存储属性名与属性值的文件,如“.ini”、“.properties”文件;
◼ Properties 擅长处理属性文件,可以很方便地实现对属性文件的读写操作;
提供load()方法加载属性文件,store()方法保存属性文件;
提供getProperty()方法读取某个属性,setProperty()方法修改某个属性。
# DB CONFIG
username=nowcoder
password=12345678
import java.io.IOException;
import java.util.Properties;
public class MapDemo3 {
public static void main(String[] args) {
Properties properties = new Properties();
try {
// 相对路径: 以编译后的项目的根目录为起点.
properties.load(MapDemo3.class.getClassLoader()
.getResourceAsStream("resources/db.properties"));
String s1 = properties.getProperty("username");
String s2 = properties.getProperty("password");
System.out.println(s1 + ", " + s2);
} catch (IOException e) {
throw new RuntimeException("加载资源文件失败!", e);
}
}
}
TreeMap
TreeMap是一个红黑树的数据结构,在存储键值对时,它按照key对键值对排序。
◼自然排序
1.对key进行比较,并根据key按照由小到大的顺序排列键值对;
2.所有的key应该是同一个类型,且必须实现Comparable接口;(原则和TreeSet一致)
◼定制排序
1.创建TreeMap时,传入一个Comparator类型的对象;
2.该对象负责对所有的key进行比较,此时不要求key实现Comparable接口。
import java.util.Comparator;
import java.util.TreeMap;
public class MapDemo4 {
public static void main(String[] args) {
TreeMap map = null;
// 自然排序
map = new TreeMap();
map.put("Lily", 90);
map.put("Mary", 80);
map.put("John", 70);
map.put("Lucy", 60);
map.put("Tony", 50);
map.put("Lisa", 40);
System.out.println(map);
//第一个和最后一个key
System.out.println(map.firstKey() + ", " + map.lastKey());
//Lucy前一个和后一个key
System.out.println(map.lowerKey("Lucy") + ", " + map.higherKey("Lucy"));
//返回前面的所有key
System.out.println(map.headMap("Lucy"));
//返回自己和后面的所有key
System.out.println(map.tailMap("Lucy"));
/前包含后不包含的情况
System.out.println(map.subMap("Lily", "Mary"));
// 定制排序-匿名内部类实现Comparator类型的对象
map = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
String s1 = (String) o1;
String s2 = (String) o2;
if (s1 == null && s2 == null) {
return 0;
} else if (s1 == null) {
return 1;
} else if (s2 == null) {
return -1;
} else {
// return s1.compareTo(s2) * (-1);
return s2.compareTo(s1);//等同于上方注释
}
}
});
map.put("Lily", 90);
map.put("Mary", 80);
map.put("John", 70);
map.put("Lucy", 60);
map.put("Tony", 50);
map.put("Lisa", 40);
System.out.println(map);
}
}
6.7 Collections工具类
Collections是一个操作集合的工具类,它提供了4类集合操作:
1.强大的排序:针对List集合提供了众多的排序方法;
2.查找与替换:针对Collection提供了众多的查找和替换元素的方法;
3.创建不可变集合:提供3类方法(空的/唯一/只读)来创建一个不可变的集合;
4.线程同步的集合:将指定的集合包装成线程同步的集合,以解决线程安全问题。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
public class CollectionsDemo {
public static void main(String[] args) {
// Collections针对List集合提供了众多的排序方法
List scores = new ArrayList();
scores.add(70);
scores.add(50);
scores.add(90);
scores.add(80);
scores.add(60);
System.out.println(scores);//按存入顺序
//自然排序,从小到大
Collections.shuffle(scores);
System.out.println(scores);
//注意sort可以第二个参数传递Comparator类型的对象来实现定制排序
//可以查看上面的TreeMap中的相关样例了解,当前默认是从小到大
Collections.sort(scores);
System.out.println(scores);
//由大到小
Collections.reverse(scores);
System.out.println(scores);
// 查找,替换
// Collection找到最大的
Object max = Collections.max(scores);
System.out.println(max);
// Collection找到最小的
Object min = Collections.min(scores);
System.out.println(min);
// List找到对应值的索引
int index = Collections.binarySearch(scores, 70);
System.out.println(index);
// List将所有60替换成65
Collections.replaceAll(scores, 60, 65);
System.out.println(scores);
// 不可变集合(用的较少,只读的集合)
List list = Collections.emptyList();
System.out.println(list);
// list.add(100);报错
Set set = Collections.singleton(200);
System.out.println(set);
// set.add(300);报错
//以原本的list的基础创建一个不可改的
List scoreList = Collections.unmodifiableList(scores);
System.out.println(scoreList);
// scoreList.add(30);报错
}
}
6.8hashcode机制
◼散列值概念
1.Hash,一般翻译做散列,或音译为哈希;
2.散列是一种算法,利用该算法可以将任意长度的输入,转换成固定长度的输出;
3.这是一种将任意长度的消息压缩成固定长度的消息的算法,其输出就是散列值。
◼ hashCode()
1.Object类中定义的hashCode()方法,就是用于返回该对象的散列值;
2.Object类对此方法采用默认实现,即返回该对象在内存中的物理地址;
3.子类通常需要重写hashCode()方法,根据封装的数据,计算出合理的散列值。
散列表原理
1.Hashtable,译作散列表,其内部利用散列值决定元素存放的位置;
2.HashMap,比Hashtable更新的API,存储原理与Hashtable一致;
3.HashSet,采用HashMap实现,因此存储原理也与Hashtable一致。
1.散列表采用链表数组实现,数组的每个位置称为桶或槽;
2.对象的散列值对桶个数求余,就是对象在数组中的索引;
3.若索引对应桶中没有其他元素,则将对象直接插入桶中;
4.若索引对应桶中已有元素,则将新对象与桶中对象比较,若相等则放弃插入,若不相等则将其链接到桶中最后一个元素之后。
(因为map中不允许相同的键,通过以上方式可以更好的存储)
hashCode()& equals()
1.散列值可以是任何整数,包括正数或负数;
2.hashCode()、equals()的定义必须兼容,规则是:
如果两个对象通过equals()比较返回true,这两个对象的hashCode()值也必须相同。
7. 泛型
7.1 泛型基础
以下程序会出现以下问题:
1.集合对元素类型没有任何限制,可能不小心存入你并不期望的类型的数据,导致程序运行时报错;
2.在对象存入集合后,集合丢失了对象的类型信息,统一的当做Object处理,经常需要强制类型转换。
List list = new ArrayList();
list.add("John");
list.add("Mary");
list.add("Lily");
list.add(100000);
Collections.sort(list);
for (Object obj : list) {
String name = (String) obj;
System.out.println(name.toUpperCase());//将字符串中的所有字符转换为大写形式
}
1.从Java 5开始,Java引入了“参数化类型”的概念,这种参数化类型被称为泛型;
2.泛型允许在创建集合时指定集合元素的类型,则集合中只能保存这种类型的对象。
// Java 5
List<String> list = new ArrayList<String>();
Map<String,Double> map = new HashMap<String,Double>();
// Java 7
List<String> list = new ArrayList<>(); // 菱形语法
Map<String,Double> map = new HashMap<>(); // 菱形语法
import java.util.*;
public class GenericDemo1 {
public static void main(String[] args) {
List<String> names = new ArrayList<String>();
names.add("John");
names.add("Mary");
names.add("Lily");
// names.add(100000);
for (String name : names) {
System.out.println(name.toUpperCase());//将字符串中的所有字符转换为大写形式
}
// Java 5
Set<Double> set1 = new HashSet<Double>();
Map<String, Double> map1 = new HashMap<String, Double>();
// Java 7
Set<Double> set2 = new HashSet<>();
Map<String, Double> map2 = new HashMap<>();
}
}
集合中的泛型定义
public interface List<E> extends Collection<E> {
boolean add(E e);
Iterator<E> iterator();
}
public interface Map<K, V> {
V put(K key, V value);
Set<Map.Entry<K, V>> entrySet();
}
7.2 自定义泛型
泛型类/接口
class Foo<T> {
private T data;
public Foo(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
1.允许在定义接口、类、方法时声明类型形参,该类型形参可以在整个接口、类、方法中当成普通类型使用;
2.类型形参将在声明变量、创建对象、调用方法时动态地指定,即传入实际的类型参数(可称作类型实参)。
泛型类的子类
为泛型类定义子类时,不能在父类上包含类型形参,但可以包含类型实参;
因为这种情况下,不是在定义父类,而是在使用父类,使用时需传入实参。
◼错误的示范
class Sub extends Foo {} //错误的示范
◼正确的示范
class Sub extends Foo<String> {} // 子类中T都将被替换成String
class Sub extends Foo {} // 可以不为类型形参传入类型实参
import java.util.ArrayList;
import java.util.List;
public class GenericDemo2 {
public static void main(String[] args) {
// 使用泛型类
Foo<String> f1 = new Foo<>("World");
System.out.println(f1.getData().toUpperCase());
Foo<Integer> f2 = new Foo<>(100);
System.out.println(f2.getData().doubleValue());
// 使用泛型类的子类
Alpha alpha = new Alpha("China");
System.out.println(alpha.getData().toUpperCase());
Beta beta = new Beta(200.0);
System.out.println(beta.getData().toString());
// 泛型类不是一个真实的类型,下面两个类是同一个类型
List<String> list1 = new ArrayList<>();
List<Double> list2 = new ArrayList<>();
System.out.println(list1.getClass().toString());//输出ArrayList的类型
System.out.println(list2.getClass().toString());//输出ArrayList的类型
System.out.println(list1.getClass() == list2.getClass());
}
}
// 定义泛型类(接口)
class Foo<T> {
private T data;
public Foo() {}
public Foo(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
// 定义泛型类的子类(接口)
class Alpha extends Foo<String> {
public Alpha() {}
public Alpha(String data) {
super(data);
}
@Override
public String getData() {
return super.getData();
}
}
class Beta extends Foo {
public Beta() {}
public Beta(Object data) {
super(data);
}
@Override
public Object getData() {
return super.getData();
}
}
7.3 泛型高级特性
设置类型形参的上限
在定义类型形参时可以设置上限:
class Foo<T extends Number> {}
上述声明表示,传入的类型实参要么是Number类型,要么是Number的子类。
public class GenericDemo3 {
public static void main(String[] args) {
First<Integer> f1 = new First<>(100);
System.out.println(f1.getData().doubleValue());
First<String> f2 = new First<>("abc");
System.out.println(f2.getData().toUpperCase());
Second<Integer> s1 = new Second<>(200);
System.out.println(s1.getData().doubleValue());
// Second<String> s2 = new Second<String>();
}
}
//Number是一个类型形参名,并非Number类,不起到限制父类的作用
class First<Number> {
private Number data;
public First() {
}
public First(Number data) {
this.data = data;
}
public Number getData() {
return data;
}
}
//下面这样就可以定义类型形参时设置上限
class Second<T extends Number> {
private T data;
public Second() {
}
public Second(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
类型通配符
要实现下面代码的功能,可以使用类型通配符
List<Object> objs = new ArrayList<>();
List<String> strs = new ArrayList<>();
test(objs);
test(strs);
String是Object的子类,但List<String>不是List<Object>的子类!
因为List<String>本身只是List类。
void test(List list) {}//没用
void test(List<Object> list) {}//不准确的写法
void test(List<?> list) {}//正确的写法,?是类型通配符
示例代码
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 类型通配符
*/
public class GenericDemo4 {
public static void main(String[] args) {
List<Object> objs = new ArrayList<>();
List<String> strs = new ArrayList<>();
// 错误的示范
test1(objs);
// test1(strs);
// 使用通配符
test2(objs);
test2(strs);
// 错误的示范,啥也存不了
Set<?> set = new HashSet<>();
// set.add(new Object());
}
public static void test1(List<Object> list) {
System.out.println(list);
}
// 类型通配符
public static void test2(List<?> list) {
System.out.println(list);
// 错误的示范,啥也存不了
// list.add(100);
}
}
通配符的上限
可以限制通配符的上限:
List<? extends Number>//写法和类型形参类似
上述声明表示,该集合中存放的是Number类型的对象,或者是Number子类型的对象。
import java.util.ArrayList;
import java.util.List;
public class GenericDemo5 {
public static void main(String[] args) {
// 编译不通过
// List<String> list = new ArrayList<>();
// test(list);
// 正确的使用
List<Integer> numList = new ArrayList<>();
test(numList);
}
public static void test(List<? extends Number> list) {
System.out.println(list);
// 错误的示范
// list.add(100);
}
}
泛型方法
泛型方法,就是在声明方法时定义一个或多个类型形参:
修饰符 <S, T> 返回值类型 方法名(参数列表) { ... }
1.类型形参的声明放在方法修饰符和返回值类型之间;
2.类型形参的声明放在尖括号内,多个类型形参之间以逗号分隔;
3.调用方法时,无需显示传入类型实参,因为编译器会根据参数值推断出类型实参。
import java.util.ArrayList;
import java.util.List;
public class GenericDemo6 {
public static void main(String[] args) {
String[] nameArray = {"John", "Mary", "Lucy"};
List<String> nameList = new ArrayList<>();
arrayToList(nameArray, nameList);
System.out.println(nameList);
Double[] scoreArray = {70.00, 80.00, 90.00};
List<Double> scoreList = new ArrayList<>();
arrayToList(scoreArray, scoreList);
System.out.println(scoreList);
// 不要制造迷惑,传入矛盾的参数
Integer[] numArray = {100, 200, 300};
List<Double> numList = new ArrayList<>();
// arrayToList(numArray, numList);
}
public static <T> void arrayToList(T[] array, List<T> list) {
if (array == null || list == null) {
return;
}
for (T t : array) {
list.add(t);
}
}
}
泛型方法与类型通配符
大多数的时候都可以使用泛型方法来代替类型通配符!
1.方法的参数是集合,并在方法内要向集合中添加元素,则采用泛型方法;
2.方法的多个参数之间,或者返回值与参数之间,其类型存在依赖关系,则采用泛型方法。
import java.util.ArrayList;
import java.util.List;
public class GenericDemo7 {
public static void main(String[] args) {
String[] nameArray = {"John", "Mary", "Lucy"};
List<String> nameList = new ArrayList<>();
arrayToList(nameArray, nameList);
System.out.println(nameList);
Double[] scoreArray = {70.00, 80.00, 90.00};
List<Number> scoreList = new ArrayList<>();
arrayToList(scoreArray, scoreList);
System.out.println(scoreList);
}
public static <T, S extends T> void arrayToList(S[] array, List<T> list) {
if (array == null || list == null) {
return;
}
for (S s : array) {
list.add(s);
}
}
}
擦除与转换
1.严格的泛型代码里,带泛型声明的类总是应该带着类型参数;
2.为了兼容旧的代码,也允许在使用泛型类时不指定类型实参;
3.若未指定类型实参,则它默认是定义泛型类时声明的类型形参的上限类型。
//擦除
List<String> list1 = ...;
List list2 = list1; // list2将元素当做Object处理,list1标记的String被擦除了
//转换
List list1 = ...;
List<String> list2 = list1; // 编译时通过并警告“未经检查的转换”
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
public class GenericDemo8 {
public static void main(String[] args) {
// 擦除
Anything<Integer> a = new Anything<>(100);
System.out.println(a.getData().compareTo(200));//输出-1
Anything b = a;//类型实参的上限是Number
System.out.println(b.getData().doubleValue());//输出100.0(上限是Number,只能使用Number的方法)
List<String> list1 = new ArrayList<>();
list1.add("abc");
System.out.println(list1.get(0).toUpperCase());
List list2 = list1;//类型实参的上限是Object
System.out.println(list2.get(0).toString());//只能使用Object的方法
// 转换
Queue queue = new ArrayDeque();
queue.offer("John");
queue.offer("Mary");
// 包含了隐患
Queue<String> queue1 = queue;
System.out.println(queue1.poll().toUpperCase());
// 错误的示范
Queue<Integer> queue2 = queue;
System.out.println(queue2.poll().doubleValue());
}
}
class Anything<T extends Number> {
private T data;
public Anything(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
8. IO流
8.1 File类
File是java.io包下的类,代表与平台(操作系统)无关的文件和目录:
1.File能创建、删除、重命名文件和目录,也能检测、访问文件和目录本身;
2.File不能访问文件中的内容,如果要访问内容,则需要使用输入、输出流。
文件操作与目录操作
路径分隔符:
1. Windows系统采用反斜线(\)作为路径分隔符;(java中\用于转译符)
2. Java程序中可以使用两条反斜线作为路径分隔符;
3. Java也支持使用一条正斜线(/)作为路径分隔符。
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
/**
* File
*/
public class IODemo1 {
public static void main(String[] args) throws IOException {
File file = null;
// 创建
file = new File("C:/work/alpha/1.txt");
file.createNewFile();
// 删除
// file.delete();
// 改名
// file.renameTo(new File("C:/work/alpha/2.txt"));
// 判断
System.out.println("是否存在:" + file.exists());
System.out.println("是否文件:" + file.isFile());
System.out.println("是否可读:" + file.canRead());
System.out.println("是否可写:" + file.canWrite());
System.out.println("绝对路径:" + file.isAbsolute());
// 访问
System.out.println("文件名称:" + file.getName());
System.out.println("文件路径:" + file.getPath());
System.out.println("绝对路径:" + file.getAbsolutePath());
System.out.println("上级目录:" + file.getParent());
System.out.println("文件长度:" + file.length());
System.out.println("修改时间:" + file.lastModified());
// 目录操作
file = new File("C:/work/alpha/a");
file.mkdir();
//目录的文件
System.out.println(Arrays.toString(file.listFiles()));
//上级目录的文件
System.out.println(Arrays.toString(file.getParentFile().listFiles()));
// 删除,改名,判断,访问方法对目录也适用.
// 相对路径
file = new File("abc.txt");
file.createNewFile();
System.out.println("文件路径:" + file.getPath());
System.out.println("绝对路径:" + file.getAbsolutePath());
System.out.println("上级目录:" + file.getParent());//null
System.out.println("上级目录:" + file.getAbsoluteFile().getParent());
}
}
文件过滤
1.File类的listFiles()方法可以接受一个参数,用于在列举文件时对其进行过滤;
2.File类会依次将文件传给过滤器,当过滤器返回true时,File类才会列举该文件。
两个接口:
public interface FileFilter {
boolean accept(File pathname);
}
public interface FilenameFilter {
boolean accept(File dir, String name);//更古老
}
import java.io.File;
import java.io.FileFilter;
import java.io.FilenameFilter;
import java.util.Arrays;
public class IODemo2 {
public static void main(String[] args) {
File dir = new File("C:/work/alpha");
File[] files = dir.listFiles();
//匿名实现接口
files = dir.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
// System.out.println(pathname);
if (pathname.getName().endsWith(".txt")) {
return true;
}
return false;
}
});
files = dir.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// System.out.println(dir.getName() + ", " + name);
if (name.endsWith(".txt")) {
return true;
}
return false;
}
});
System.out.println(Arrays.toString(files));
}
}
文件遍历
import java.io.File;
public class IODemo3 {
public static void main(String[] args) {
printFile("C:/work/workspace/javademo", 0);
}
/*
* alpha
* a
* - x.png
* - y.png
* - 1.txt
* - 2.txt
*/
public static void printFile(String filePath, int depth) {
File file = new File(filePath);
if (!file.exists()) {
throw new IllegalArgumentException("文件不存在!");
}
// 打印空格
for (int i = 0; i < depth; i++) {
System.out.print(" ");
}
// 打印名字
if (file.isFile()) {
System.out.print(" - ");//是文件打印横线,目录则不打印横线
}
System.out.println(file.getName());
// 目录递归
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
printFile(f.getPath(), depth + 1);
}
}
}
}
8.2 IO流概述
1.IO(Input Output)用于实现对数据的输入与输出操作;
2.Java把不同的输入/输出源(键盘、文件、网络等)抽象表述为流(Stream);
3.流是从起源到接收的有序数据,程序采用同一方式可以访问不同的输入/输出源。
流的分类
◼输入流和输出流(方向)
-输入流只能读取数据,不能写入数据;
-输出流只能写入数据,不能读取数据;
◼字节流和字符流(数据)
-字节流操作的数据单元是8位的字节;
-字符流操作的数据单元是16位的字符;
◼节点流和处理流(功能)
-节点流可以直接从/向一个特定的IO设备(磁盘、网络等)读/写数据,也称为低级流;
-处理流是对节点流的连接或封装,用于简化数据读/写功能或提高效率,也称为高级流。
输入/输出的方向:
1.通常从程序运行所在内存的角度来区分;
2.数据从硬盘流向内存,通常称为输入流;
3.数据从内存流向硬盘,通常成为输出流。
流的模型
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 数据流 | DataInputStream | DataOutputStream |
8.3 流体系结构
抽象基类
1.下述四个类都是抽象类,不能直接实例化;
2.下述四个类都定义了close()方法,你需要在使用流之后调用此方法将其关闭;
3.无论是否发生异常,使用流后都要尝试关闭它,所以通常在finally中关闭流;
4.下述四个类都实现了Closeable接口,因此可以在try()中创建流,以便于自动关闭。
输入流 字节数/字符数即读到了了的字节/字符的数量。
| FileInputStream | |
|---|---|
| int read() | 读取下一个字节;(一个一个读) |
| int read(byte[] b) | 读取下一批字节,将其存入数组,返回读取的字节数; |
| int read(byte[] b, int off, int len) | 从off开始最多读取len个字节,将其存入数组,返回读取的字节数; |
int read(byte[] b)中数组长度是多少就读多少个字节,当什么都没读到的时候会返回-1,下面同样。
| Reader | |
|---|---|
| int read() | 读取下一个字符; |
| int read(char[] c) | 读取下一批字符,将其存入数组,返回读取的字符数; |
| int read(char[] c, int off, int len) | 从off开始最多读取len个字符,将其存入数组,返回读取的字符数; |
输出流
| OutputStream | 功能说明 |
|---|---|
void write(int b) | 输出指定的字节 |
void write(byte[] b) | 输出指定的字节数组 |
void write(byte[] b, int off, int len) | 输出指定的字节数组,从off开始最多输出len个字节 |
| Writer | 功能说明 |
|---|---|
void write(int c) | 输出指定的字符 |
void write(char[] c) | 输出指定的字符数组 |
void write(char[] c, int off, int len) | 输出指定的字符数组,从off开始最多输出len个字符 |
void write(String str) | 输出指定的字符串 |
void write(String str, int off, int len) | 输出指定的字符串,从off开始最多输出len个字符 |
文件流(属于节点流)
这4个类都是节点流(效率低,建议用缓冲流,效率更高),会直接和指定的文件关联,即实例化时传入文件路径!
| 分类 | 字节输入 | 流字节输出 | 流字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
import java.io.*;
public class IODemo4 {
public static void main(String[] args) {
// copyFile("C:/work/alpha/nk-head.png", "C:/work/alpha/nk-head-副本.png");
// copyFile("C:/work/alpha/IODemo1.java", "C:/work/alpha/IODemo1-副本.java");
copyTextFile("C:/work/alpha/IODemo1.java", "C:/work/alpha/IODemo1-拷贝.java");
}
//字节流文件拷贝
public static void copyFile(String srcFilePath, String destFilePath) {
try (
FileInputStream fis = new FileInputStream(srcFilePath);
FileOutputStream fos = new FileOutputStream(destFilePath);
) {
byte[] bytes = new byte[128];
int len = 0; // 实际读取的字节数
while ((len = fis.read(bytes, 0, 128)) > 0) {
fos.write(bytes, 0, len);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//字符流文件拷贝
public static void copyTextFile(String srcFilePath, String destFilePath) {
try (
FileReader fr = new FileReader(srcFilePath);
FileWriter fw = new FileWriter(destFilePath);
) {
char[] chars = new char[128];
int len = 0; // 实际读取的字符数
while ((len = fr.read(chars, 0, 128)) > 0) {
// System.out.print(String.valueOf(chars, 0, len));
fw.write(chars, 0, len);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
缓冲流(属于处理流)
1.这四个类都是处理流,需要关联对应的节点流,即实例化时需传入节点流实例;
2.缓冲流内部维护了一个缓冲区,通过与缓冲区的交互,减少与设备的交互次数,效率高;
3.使用缓冲输入流时,它每次会读取一批数据将缓冲区填满,每次调用读取方法并不是直接从设备取值,而是从缓冲区取值,当缓冲区为空时,它会再一次读取数据,将缓冲区填满;
4.使用缓冲输出流时,每次调用写入方法并不是直接写入到设备,而是写入缓冲区,当缓冲区填满时它会自动刷入设备,也可以调用flush()方法触发刷入(关闭流时会自动调flush())。
| 分类 | 字节输入 | 流字节输出 | 流字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
import java.io.*;
public class IODemo5 {
public static void main(String[] args) {
long start = System.currentTimeMillis();
copyFile("C:/work/alpha/壁纸.jpg", "C:/work/alpha/壁纸-副本.jpg");
long end = System.currentTimeMillis();
System.out.println("用时: " + (end - start));
}
public static void copyFile(String scrFilePath, String destFilePath) {
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(scrFilePath));
//缓冲流传入节点流实例
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(destFilePath));
) {
byte[] bytes = new byte[128];
int len = 0;
while ((len = bis.read(bytes, 0, 128)) > 0) {
bos.write(bytes, 0, len);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
转换流(属于处理流)
1.这2个类都是处理流,需要关联对应的节点流,即实例化时需传入节点流实例;
2.Scanner所提供的输入方法,其底层是采用InputStreamReader类实现的;
3.PrintStream所提供的输出方法,其底层是采用OutputStreamWriter实现的。
| 分类 | 字节输入 | 流字节输出 | 流字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 转换流 | InputStreamReader | OutputStreamWriter |
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class IODemo6 {
public static void main(String[] args) {
try (
InputStreamReader r = new InputStreamReader(System.in);//传入了标准输入System.in,代表键盘
BufferedReader br = new BufferedReader(r);
) {
String line = null;
while ((line = br.readLine()) != null) {//读一行
if (line.equalsIgnoreCase("exit")) {//读到一行是exit则退出
break;
}
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印流(属于处理流)
1.这2个类都是处理流,需要关联对应的节点流,即实例化时需传入节点流实例;
2.System.out就是PrintStream类型;
3.PrintStream、PrintWriter的功能和方法基本相同,后者的设计更合理(晚)。
| 分类 | 字节输入 | 流字节输出 | 流字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 打印流 | PrintStream | PrintWriter |
import java.io.*;
public class IODemo7 {
public static void main(String[] args) {
// testPrintStream();
testPrintWriter();
}
//字节形式打印
public static void testPrintStream() {
try (
FileOutputStream fos = new FileOutputStream("C:/work/alpha/a.txt");
PrintStream ps = new PrintStream(fos);
) {
ps.println("白日依山尽,");//通过节点流打印到文件
ps.println("黄河入海流.");//不同于System.out.println的输出到终端显示器
ps.println("欲穷千里目,");
ps.println("更上一层楼.");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//字符形式打印
public static void testPrintWriter() {
try (
FileWriter fw = new FileWriter("C:/work/alpha/b.txt");
PrintWriter pw = new PrintWriter(fw);
) {
pw.println("白日依山尽,");
pw.println("黄河入海流.");
pw.println("欲穷千里目,");
pw.println("更上一层楼.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
重定向
在Java中:
1.System.in 代表标准输入,默认情况下代表键盘;
2.System.out代表标准输出,默认情况下代表显示器;
System类提供三个重定向方法:
1.public static void setIn(InputStream in)
2.public static void setOut(PrintStream out)
3.public static void setErr(PrintStream err)
这些重定向方法,用于修改标准输入、标准输出、错误输出的目标设备。
import java.io.*;
import java.util.Scanner;
public class IODemo8 {
public static void main(String[] args) {
// testRedirectOutput();
testRedirectInput();
}
//由于System.out是一个PrintStream,所以setOut必须用PrintStream打印流
public static void testRedirectOutput() {
try (
PrintStream ps = new PrintStream(
new FileOutputStream("C:/work/alpha/out.txt"));
) {
System.setOut(ps); //通过这里改变标准输出从显示器到文件
System.out.println("白日依山尽,");
System.out.println("黄河入海流.");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//由于System.in是一个FileInputStream(句柄 0,对应键盘或重定向文件),所以setIn用FileInputStream
public static void testRedirectInput() {
try (
FileInputStream fis = new FileInputStream("C:/work/alpha/out.txt");
) {
//通过这里改变标准输入从键盘到文件
System.setIn(fis);
//这里可以不用setIn后传System.in,可以直接传入fis
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
System.out.println(scanner.next());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
RandomAccessFile类
1.RAF类支持随机访问文件,即程序可以跳转到文件的任意位置(可指定)来访问文件;
2.RAF包含了丰富的功能,既支持读取文件内容,也支持向文件输出数据;
3.RAF允许自由定位文件指针,该指针既可以向前移动,也可以向后移动;
4.RAF包含的输入和输出的方法,与InputStream和OutputStream类似。
RandomAccessFile类只能访问文件
long getFilePointer(),返回文件指针当前所指向的位置;
void seek(long pos),将文件指针定位到指定位置(pos)。
示例
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
public class IODemo9 {
public static void main(String[] args) {
try (
RandomAccessFile raf =
new RandomAccessFile("C:/work/alpha/out.txt", "rw");//r只读,rw读写
) {
// 定位至末尾
raf.seek(raf.length());
raf.write("欲穷千里目,\n".getBytes());//getBytes()字符串转字节,这里应该是使用utf-8
raf.write("更上一层楼.\n".getBytes());//getBytes("ISO8859-1")可以解决下面问题,但是该编码不支持中文
// 定位至开头
raf.seek(0);
String line = null;
while ((line = raf.readLine()) != null) {
// String -> bytes (UTF-8)
// bytes -> String (ISO8859-1)
// String -> bytes (ISO8859-1)
// bytes -> String (UTF-8) raf使用该规则
byte[] bytes = line.getBytes("ISO8859-1");
line = new String(bytes, "UTF-8");
System.out.println(line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.4 序列化
序列化机制
序列化机制可以将对象转换成字节序列,这些字节序列可以保存在磁盘上,也可以在网络中传输,并允许程序将这些字节序列再次恢复成原来的对象。
1.对象的序列化(Serialize),是指将一个Java对象写入IO流中;
2.对象的反序列化(Deserialize),是指从IO流中恢复该Java对象。
如何支持序列化
1.若对象要支持序列化机制,则它的类需要实现Serializable接口;
2.该接口是一个标记接口,它没有提供任何方法,只是标明该类是可以序列化的;
3.Java的很多类已经实现了Serializable接口,如包装类、String、Date等。
实现序列化
使用对象流ObjectInputStream和ObjectOutputStream(处理流)!
◼序列化
1.创建ObjectOutputStream对象;
2.调用ObjectOutputStream对象的writeObject()方法,以输出对象序列。
◼反序列化
1.创建ObjectInputStream对象;
2.调用ObjectInputStream对象的readObject()方法,将对象序列恢复为对象。
import java.io.*;
public class IODemo10 {
public static void main(String[] args) {
// testSerialize();
testDeserialize();
}
//序列化
public static void testSerialize() {
try (
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("C:/work/alpha/car.txt"));
) {
oos.writeObject(new Car("奔驰", "红色", 300));
oos.writeObject(new Car("宝马", "蓝色", 400));
oos.writeObject(new Car("奥迪", "黑色", 500));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//反序列化
public static void testDeserialize() {
try (
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("C:/work/alpha/car.txt"));
) {
System.out.println(ois.readObject());
System.out.println(ois.readObject());
System.out.println(ois.readObject());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Car implements Serializable {
private String brand;
private String color;
private int maxSpeed;
public Car(String brand, String color, int maxSpeed) {
System.out.println("Init Car.");
this.brand = brand;
this.color = color;
this.maxSpeed = maxSpeed;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public int getMaxSpeed() {
return maxSpeed;
}
public void setMaxSpeed(int maxSpeed) {
this.maxSpeed = maxSpeed;
}
@Override
public String toString() {
return "Car{" +
"brand='" + brand + '\'' +
", color='" + color + '\'' +
", maxSpeed=" + maxSpeed +
'}';
}
}
/**反序列化的输出过程,序列化和反序列化不会调用构造器
1. ois.readObject() → 反序列化,恢复对象数据 ✅
2. 得到Car对象引用 → 对象已在内存中 ✅
3. System.out.println() → 准备输出 ✅
4. 自动调用car.toString() → 生成格式化的字符串 ✅
5. 输出字符串到控制台 → 显示结果 ✅
/**
序列化的规则
序列化的目的是将对象中的数据(成员变量)转为字节序列,和成员方法无关;
为了正确地序列化某个对象,这个对象以及它所对应的类需要符合如下的规则:
1.该对象中引用类型的成员变量也必须是可序列化的; 2.该类的直接或间接的父类,要么具有无参构造器,要么也是可序列化的; 3.一个对象只会被序列化一次,再次序列化时仅仅会输出它的序列号而已。
1.每个被序列化的对象都有一个序列号;
2.在序列化对象之前,程序会先检查它是否被序列化过,若对象没有被序列化过,
程序会将其转为字节序列;若对象已被序列化过,程序会直接输出它的序列号。
验证一个对象只会被序列化一次
import java.io.*;
public class IODemo11 {
public static void main(String[] args) {
// testSerialize();
testDeserialize();
}
public static void testSerialize() {
try (
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("C:/work/alpha/stu.txt"));
) {
Teacher t = new Teacher("唐僧");
Student s1 = new Student("悟空", t);
Student s2 = new Student("八戒", t);
oos.writeObject(t);
oos.writeObject(s1);//t是成员变量也会被序列化
oos.writeObject(s2);//t是成员变量也会被序列化
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void testDeserialize() {
try (
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("C:/work/alpha/stu.txt"));
) {
Teacher t = (Teacher) ois.readObject();
Student s1 = (Student) ois.readObject();
Student s2 = (Student) ois.readObject();
System.out.println(t);
System.out.println(s1);
System.out.println(s2);
//验证对象没有被重复序列化
System.out.println(s1.getTeacher() == s2.getTeacher());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Teacher implements Serializable {
private String name;
public Teacher(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Teacher{" +
"name='" + name + '\'' +
'}';
}
}
class Student implements Serializable {
private String name;
private Teacher teacher;
public Student(String name, Teacher teacher) {
this.name = name;
this.teacher = teacher;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", teacher=" + teacher +
'}';
}
}
序列化的版本
一个常见的场景 程序中已经定义了某个类: 1.创建该类的实例,并将这个实例序列化,保存在磁盘上; 2.升级这个类,例如增加、删除、修改这个类的成员变量; 3.反序列化该类的实例,即从磁盘上恢复修改之前保存的数据。
定义类的序列化版本,在反序列化时,只要对象中所存的版本和当前类的版本一致,就允许做恢复数据的操作,否则将会抛出序列化版本不一致的错误。
Java允许以下列形式来定义序列化版本:
private static final long serialVersionUID = ...;
1.如果没有显示定义serialVersionUID,则 JVM 会根据类的信息自动计算出它的值, 由于升级前后类的内容发生了变化,该值的计算结果通常不同,这会导致反序列化失败;
2.最好在序列化的类中显示定义serialVersionUID,这样即便对象被序列化后, 它所对应的类被修改了,由于版本号是一致的,所以该对象依然可以被正确的反序列化。
在反序列化时,只有那些成功匹配上的成员变量会被恢复!
import java.io.*;
public class IODemo12 {
public static void main(String[] args) {
// testSerialize();
testDeserialize();
}
public static void testSerialize() {
try (
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("C:/work/alpha/dri.txt"));
) {
Driver d = new Driver("Tom", 'M', 23);
// d.setLicense("H0527");
// d.setLevel(5);
oos.writeObject(d);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void testDeserialize() {
try (
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("C:/work/alpha/dri.txt"));
) {
Driver d = (Driver) ois.readObject();
System.out.println(d);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Driver implements Serializable {
private static final long serialVersionUID = 847704670584248289L;//
private String name;
private char gender;
private int age;
private String licenseNO;
// private int level;
private int order;
public Driver(String name, char gender, int age) {
this.name = name;
this.gender = gender;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getGender() {
return gender;
}
public void setGender(char gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getLicenseNO() {
return licenseNO;
}
public void setLicenseNO(String licenseNO) {
this.licenseNO = licenseNO;
}
public int getOrder() {
return order;
}
public void setOrder(int order) {
this.order = order;
}
@Override
public String toString() {
return "Driver{" +
"name='" + name + '\'' +
", gender=" + gender +
", age=" + age +
", licenseNO='" + licenseNO + '\'' +
", order=" + order +
'}';
}
}
transient关键字
transient关键字用于修饰成员变量,表示序列化时将会忽略它;
transient关键字只能修饰成员变量,不能修饰类中其他的内容。
在某些场景里,不希望序列化某个成员变量: 1.该成员变量是敏感信息,如用户密码、银行账号等; 2.该成员变量是引用类型,但它没有实现序列化接口。
import java.io.*;
public class IODemo13 {
public static void main(String[] args) {
testSerialize();
testDeserialize();
}
public static void testSerialize() {
try (
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("C:/work/alpha/user.txt"));
) {
User user = new User("john", "123456");
user.setEmail("john@gmail.com");
user.setPhone("18612345678");
oos.writeObject(user);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void testDeserialize() {
try (
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("C:/work/alpha/user.txt"));
) {
System.out.println(ois.readObject());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class User implements Serializable {
private static final long serialVersionUID = -7169563013077451214L;
private String username;
private transient String password;
private String email;
private String phone;
public User(String username, String password) {
this.username = username;
this.password = password;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", password='" + password + '\'' +
", email='" + email + '\'' +
", phone='" + phone + '\'' +
'}';
}
}
自定义序列化
自定义序列化,可以让程序自主控制序列化及反序列化成员变量的方式,
自定义序列化,可以通过在类中定义如下具有特殊签名的方法进行实现:
◼写入对象的成员变量
private void writeObject(ObjectOutputStream out) throws IOException;
◼恢复对象的成员变量
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException;
import java.io.*;
public class IODemo14 {
public static void main(String[] args) {
testSerialize();
testDeserialize();
}
public static void testSerialize() {
try (
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("C:/work/alpha/customer.txt"));
) {
Customer c = new Customer("john", "123456");
c.setEmail("john@gmail.com");
oos.writeObject(c);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void testDeserialize() {
try (
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("C:/work/alpha/customer.txt"));
) {
System.out.println(ois.readObject());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Customer implements Serializable {
private static final long serialVersionUID = -4332797723908658766L;
private String username;
private String password;
private String email;
public Customer(String username, String password) {
this.username = username;
this.password = password;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "Customer{" +
"username='" + username + '\'' +
", password='" + password + '\'' +
", email='" + email + '\'' +
'}';
}
private void writeObject(ObjectOutputStream out) throws IOException {
System.out.println("写入对象...");
out.writeObject(this.username);
out.writeObject(new StringBuilder(this.password).reverse().toString());
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
System.out.println("恢复对象...");
this.setUsername(in.readObject().toString());
this.setPassword(new StringBuilder(in.readObject().toString()).reverse().toString());
}
}
8.5 NIO
1.NIO(New IO),是Java从4开始陆续增加的IO处理的新功能,这些类都被放在java.nio包及其子包下,并且java.io包中的很多类也以NIO为基础进行了改写;
2.NIO采用内存映射文件的方式来处理输入和输出,它将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了,这比传统的输入和输出的方式要高效很多;
3.Channel和Buffer是NIO中的两个核心对象:
-Channel(通道)是对传统的输入/输出系统的模拟,所有数据都要通过通道传输;
-Buffer(缓冲)是一个容器(数组),是程序与Channel沟通的桥梁,程序向Channel写入的数据都要先放到Buffer中,程序从Channel中读取的数据也会被放到Buffer中。
Buffer
◼ Buffer是抽象类,它有如下子类:
ByteBuffer、CharBuffer、 //用的最频繁 ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer;
◼只能通过静态方法实例化Buffer:
public static CharBuffer allocate(int capacity);
Buffer的核心是4个成员变量: 1.容量(capacity):Buffer可以存储的最大数据量,该值不可改变; 2.界限(limit):Buffer中可以读/写数据的边界,limit之后的数据不能访问; 3.位置(position):下一个可以被读写的数据的位置(索引); 4.标记(mark):Buffer允许将位置直接定位到该标记处,这是一个可选的属性;
上述变量满足如下的关系:0 <= mark <= position <= limit <= capacity

Buffer使用示例:
第三张图是执行flip()后的情况,从第二张图开始,limit会取代position的位置,后position回到起点。
第4张图是执行clear()后的情况,不会清除数据,只是重置指针,put()存入数据还是从position开始,会覆盖数据
上面执行流程的的示例代码:
import java.nio.Buffer;
import java.nio.CharBuffer;
public class NIODemo1 {
public static void main(String[] args) {
// 创建对象
CharBuffer buffer = CharBuffer.allocate(8);
printBufferStatus(buffer, "创建");
// 放入数据
buffer.put('A').put('B').put('C');
printBufferStatus(buffer, "放入");
// 准备取出
buffer.flip();
printBufferStatus(buffer, "准备");
// 取出数据
System.out.println("###:\t" + buffer.get() + ", " + buffer.get());
printBufferStatus(buffer, "取出");
// 重置指针
buffer.clear();
printBufferStatus(buffer, "重置");
// 绝对位置,不会移动指针
System.out.println("###:\t" + buffer.get(0) + ", " + buffer.get(1));
printBufferStatus(buffer, "绝对");
}
//打印buffer的状态
public static void printBufferStatus(Buffer buffer, String action) {
System.out.println(
new StringBuilder()
.append(action).append(":\t")
.append("position=").append(buffer.position())//打印position成员对象
.append(", limit=").append(buffer.limit())//同上
.append(", capacity=").append(buffer.capacity()).toString()//同上
);
}
}
Channel接口
◼ Channel的实现类
FileChannel、//文件通道,用来读写文件,用的比较多
SocketChannel、ServerSocketChannel、DatagramChannel、//解决客户端服务端通信
Pipe.SourceChannel、Pipe.SinkChannel;//解决不同进程的通道
◼ Channel的实例化
1.各个Channel类提供的open()方法;
2.FileInputStream、FileOutputStream、RandomAccessFile类提供了getChannel()方法,可以直接返回FileChannel。
◼ Channel的方法
1.map()方法用于将Channel对应的数据映射成ByteBuffer;
2.read()方法有一系列重载的形式,用于从Buffer中读取数据;
3.write()方法有一系列重载的形式,用于向Buffer中写入数据。
文件拷贝示例
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* Channel
*/
public class NIODemo2 {
public static void main(String[] args) {
copyFile("C:/work/alpha/壁纸.jpg", "C:/work/alpha/壁纸-拷贝.jpg");
copyFile("C:/work/alpha/IODemo1.java", "C:/work/alpha/IODemo1-拷贝.java");
appendFile("C:/work/alpha/out.txt", "欲穷千里目,\n更上一层楼.\n");
}
//拷贝方法
public static void copyFile(String srcFilePath, String destFilePath) {
try (
FileChannel in = new FileInputStream(srcFilePath).getChannel();
FileChannel out = new FileOutputStream(destFilePath).getChannel();
) {
// 整体映射,一次存入内存
//用map()方法将Channel对应的数据映射成ByteBuffer
//0, in.size()即从头到末尾,这个大文件可能会导致文件泄露
// ByteBuffer buffer = in.map(FileChannel.MapMode.READ_ONLY, 0, in.size());
// out.write(buffer);
// 批次映射,分批次存入内存
ByteBuffer buffer = ByteBuffer.allocate(1024 * 100);
//in.read(buffer)往buffer中读数据,数据读到头返回-1
while (in.read(buffer) != -1) {
buffer.flip();//buffer改变指针位置准备被读
out.write(buffer);//读buffer
buffer.clear();//重置buffer指针,准备下次再写入
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//文件内容追加方法
public static void appendFile(String filePath, String content) {
try (
FileChannel channel =
new RandomAccessFile(filePath, "rw").getChannel();
) {
// 定位至文件末尾
channel.position(channel.size());
// 创建Buffer
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put(content.getBytes());//String转Bytes
buffer.flip();
channel.write(buffer);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Charset抽象类(字符集)
1.编码(Encode):将明文的字符序列转换成二进制序列;
2.解码(Decode):将二进制序列转换成明文的字符序列;
3.字符集(charset):字符序列与字节序列转换时所遵循的规则。
若编码时采用的字符集与解码时采用的字符集不一致,就会产生乱码。
Charset是抽象类,用来处理字符序列与字节序列之间的转换!
◼实例化
Charset charset = Charset.forName("UTF-8");
◼编码与解码
CharsetEncoder encoder = charset.newEncoder();
CharsetDecoder decoder = charset.newDecoder();
编码:CharsetEncoder提供了encode()方法,可以将CharBuffer转为ByteBuffer; 解码:CharsetDecoder提供了decode()方法,可以将ByteBuffer转为CharBuffer。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
public class NIODemo3 {
//这段代码主要是获得encoder、decoder
public static Charset charset = Charset.forName("UTF-8");
public static CharsetEncoder encoder = charset.newEncoder();
public static CharsetDecoder decoder = charset.newDecoder();
//程序入口
public static void main(String[] args) {
// testEncoder();
testDecoder();
}
//编码
public static void testEncoder() {
try (
FileChannel channel =
new FileOutputStream("C:/work/alpha/nio.txt").getChannel();
) {
// 字符缓冲
CharBuffer charBuffer = CharBuffer.allocate(1024);
charBuffer.put("白日依山尽,\n").put("黄河入海流.\n");
charBuffer.flip();
// 字符缓冲转字节缓冲
ByteBuffer byteBuffer = encoder.encode(charBuffer);
channel.write(byteBuffer);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//解码
public static void testDecoder() {
try (
FileChannel channel =
new FileInputStream("C:/work/alpha/nio.txt").getChannel();
) {
ByteBuffer byteBuffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, channel.size());
CharBuffer charBuffer = decoder.decode(byteBuffer);
System.out.println(charBuffer.toString());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Paths、Files工具类
◼ Paths
1.Paths类提供了两个静态的get()方法,用于返回Path类型的对象; 2.Path是一个接口,代表与平台无关的路径,提供了访问路径的方法;
◼ Files
Files是一个操作文件的工具类,它提供了大量便捷的访问文件的方法。
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.function.Consumer;
public class NIODemo4 {
public static void main(String[] args) throws IOException {
// testPaths();
testFiles();
}
public static void testPaths() {
Path path = Paths.get("abc.txt").toAbsolutePath();
System.out.println(path);//路径
System.out.println(path.getRoot());//根路径(win是盘符)
System.out.println(path.getParent());//父级路径
System.out.println(path.getNameCount());//级的数量,包括abc.txt,但是除了盘符
System.out.println(path.getName(0));//第一级的路径名
System.out.println(path.getFileName());//文件名
}
public static void testFiles() throws IOException {
// 复制文件
// Files.copy(Paths.get("C:/work/alpha/out.txt"),
// new FileOutputStream("C:/work/alpha/out-副本.txt"));
// 读取文件
List<String> lines = Files.readAllLines(Paths.get("C:/work/alpha/out.txt"));
System.out.println(lines);
// 写入文件
Files.write(Paths.get("C:/work/alpha/files.txt"), lines);
// 目录逐一列举
Files.list(Paths.get("C:/work/alpha"))
.forEach(new Consumer<Path>() {//匿名实现
@Override
public void accept(Path path) {
System.out.println(path);
}
});
// 文件逐行处理
Files.lines(Paths.get("C:/work/alpha/out.txt"))
.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
}
}
9. 多线程
9.1线程基础
进程
定义:进程是处于运行过程中的程序,具有独立的功能,是系统进行资源分配和调度的独立单位。
◼独立性 进程是系统中独立存在的实体,它拥有自己独立的资源,每一个进程都拥有自己私有的地址空间,在没有经过进程本身允许的情况下,一个进程不能直接访问其他进程的地址空间;
◼动态性 进程是一个正在系统中活动的指令集合,包含了时间的概念,具有自己的生命周期和状态;
◼并发性 在单个处理器上,多个进程可以并发地执行,并且在执行时它们彼此之间不会互相的影响。
并发和并行的区别: ◼并行 在同一时刻,有多条指令在多个处理器上同时执行;
◼并发 1.在同一时刻,某一个处理器只能执行一条指令; 2.多个进程的指令可以被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果。 对于多核计算机,当进程数多于核心数时,也会存在并发的行为!
线程
1.线程扩展了进程的概念,使得同一个进程可以同时并发处理多个任务; 2.线程是进程的组成部分,一个进程可以拥有多个线程,一个线程必须有一个父进程; 3.线程不拥有系统资源,它与父进程里的其他线程共享父进程所拥有的全部系统资源。
1.系统可以同时执行多个任务,每个任务就是进程;
2.进程可以同时执行多个任务,每个任务就是线程。
线程的优点
◼容易共享内存 进程之间不能共享内存,但线程之间共享内存非常容易,因为与分隔的进程相比,线程之间的隔离程度要小,它们共享内存、文件句柄、其他每个进程应有的状态; ◼运行效率更高 系统创建进程时要为其分配系统资源,但创建线程时不需要,所以线程的运行效率更高; ◼编程方式简单 Java内置了多线程功能的支持,并不是简单地对操作系统的底层进行调度,编程更方便。
线程的创建方式
Java的线程模型
1.Java使用Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例;
2.线程用于完成一定的任务(执行一段程序流),Java使用线程执行体来代表这段程序流;
3.线程的使用过程:定义线程执行体> 创建线程对象> 调用线程对象的方法以启动线程。
方式一、继承Thread类
1.定义Thread类的子类,并重写该类的run()方法(线程体);
2.创建Thread类的子类的实例,即创建线程对象;
3.调用线程对象的start()方法,即启动这个线程。
class Foo extends Thread {
public void run () { ... }
}
public static void main(String[] args) {
new Foo().start();
}
方式二、实现Runnable接口
1.定义Runnable接口的实现类,并实现该接口的run()方法(线程体);
2.创建Runnable实现类的实例,并以此作为target来创建Thread对象;
3.调用Thread对象的start()方法来启动线程。
class Foo implements Runnable {
public void run () { ... }
}
public static void main(String[] args) {
new Thread(new Foo()).start();
}
方式三、实现Callable接口
1.定义Callable接口的实现类,并实现该接口的call()方法(线程体);
2.创建Callable接口的实例,并使用Future接口来包装Callable对象,
最后使用Future对象(线程的返回值)作为target来创建Thread对象;
3.调用Thread对象的start()方法来启动线程;
4.调用Future对象的get()方法获取线程的返回值。
class Foo implements Callable<String> {
public String call() throws Exception { ... }
}
public static void main(String[] args) {
FutureTask<String> task = new FutureTask<>(new Foo());
new Thread(task).start();
System.out.println(task.get());
}
三种方式的比较
◼继承父类的方式 -优点:编程比较简单; -缺点:线程类已经继承了Thread类,所以不能再继承其他的父类; ◼实现接口的方式 -优点:线程类只实现了接口,还可以继承于其他的父类; -缺点:编程比较麻烦;
建议采用实现Runnable接口的方式, 若需要获取返回值则采用实现Callable接口的方式。
创建线程的示例
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class ThreadDemo1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1、两个线程的并发
// new First().start();
// new First().start();
// 2、两个线程的并发
// new Thread(new Second()).start();
// new Thread(new Second()).start();
// 3、两个线程的并发
FutureTask<String> task0 = new FutureTask<>(new Third());
FutureTask<String> task1 = new FutureTask<>(new Third());
new Thread(task0).start();
new Thread(task1).start();
// main方法是主线程
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t\t" + i);
}
// 获取返回值的方法get()是阻塞方法
System.out.println("返回值-0:\t" + task0.get());
System.out.println("返回值-1:\t" + task1.get());
}
//方法一、继承Thread类
private static class First extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
//方法二、实现Runnable接口
private static class Second implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
//方法三、实现Callable接口
private static class Third implements Callable<String> {
@Override
public String call() throws Exception {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
return Thread.currentThread().getName();
}
}
}
线程的生命周期
当线程被创建后,它不会立刻进入运行状态,也不会一直处于运行状态。
在线程的生命周期中,需要经过如下5种状态: 1.新建(New) 2.就绪(Ready) 3.运行(Running) 4.阻塞(Blocked) 5.死亡(Dead)
public class ThreadDemo2 {
public static void main(String[] args) throws InterruptedException {
// 误区
// new Thread(new ThreadTask()).run();
// 新建
Thread thread0 = new Thread(new ThreadTask());
Thread thread1 = new Thread(new ThreadTask());
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "\t\t" + i);
if (i == 10) {
// 子线程就绪
thread0.start();
thread1.start();
// thread1.start();
// 强制主线程从运行到就绪
// Thread.yield();
// 主线程阻塞1ms
Thread.sleep(1);
}
}
// 子线程死亡,无法再就绪
// 因此只能对新建状态的线程调用start()方法.
// thread0.start();//错误的使用
// thread1.start();
}
private static class ThreadTask implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
}
9.2 线程控制
控制线程
线程休眠
Thread类提供了休眠方法,可以让当前线程暂停一段时间:
static void sleep(long millis)
static void sleep(long millis, int nanos)//nanos是微秒
sleep() 比较 yield()
- sleep()会让线程进入阻塞状态,而yield()会让线程进入就绪状态;
- sleep()给其他线程运行的机会,不理会其他线程的优先级,yield()考虑线程的优先级,只会给优先级相同,或优先级更高的线程执行机会。
等待线程
Thread类提供了等待方法,可以让调用方等待该线程直至它死亡:
void join()
void join(long millis)//调用方等待会等待millis毫秒,除非该线程死亡或时间耗尽
void join(long millis, int nanos)
示例
void main(String[] args) {
Thread thread = ...;
thread.start();
thread.join();
...
}
后台线程
1.后台线程,也叫守护线程,或精灵线程; 2.它是在后台运行的,它的任务是为其他线程提供服务; 3.如果所有的前台线程都死亡,则后台线程会自动死亡。 4.线程默认是前台线程,Thread类提供如下方法来设置后台线程:
void setDaemon(boolean on)//设置后台线程
boolean isDaemon()//查看线程是否是后台线程
前台线程都死亡后,JVM会通知后台线程死亡,但从它接收指令到做出响应,需要一定的时间。
线程的优先级
1.线程运行时拥有优先级,优先级高的线程则拥有较多的运行机会; 2.线程默认的优先级与它的父线程相同(比如对于main中创建的线程,则mian是父线程),而主线程具有普通优先级; 3.Thread类提供了如下的成员,来处理线程的优先级:
static int MAX_PRIORITY; // 最高的优先级,实际上是10
static int MIN_PRIORITY; // 最低的优先级,实际上是1
static int NORM_PROORITY; // 默认的优先级,实际上是5
int getPriority()//得到线程的优先级
void setPriority(int newPriority)//改变线程的优先级
线程的优先级需要操作系统的支持,虽然Java支持10种优先级,但是操作系统支持的优先级可能少于10种,所以最好不要通过数字设置线程的优先级,而是尽可能地采用静态变量来指定。
控制线程示例
public class ThreadDemo3 {
public static void main(String[] args) throws InterruptedException {
// testJoinThread();//等待线程示例
// testDaemonThread();//后台线程示例
testThreadPriority();//优先级线程示例
}
//线程体
private static class JoinThreadTask implements Runnable {
@Override
public void run() {
for (int i = 0; i < 30; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
//等待线程
public static void testJoinThread() throws InterruptedException {
new Thread(new JoinThreadTask()).start();//Thread-0
for (int i = 0; i < 30; i++) {
System.out.println(Thread.currentThread().getName() + "\t\t" + i);//主线程
if (i == 10) {
Thread thread = new Thread(new JoinThreadTask());//Thread-1
thread.start();
thread.join();//让调用方(main)等Thread-1执行
}
}
}
//线程体
private static class DaemonThreadTask implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
// 后台线程
public static void testDaemonThread() {
Thread thread = new Thread(new DaemonThreadTask());
thread.setDaemon(true);//设置后台线程Thread-0
thread.start();
for (int i = 0; i < 10; i++) {
//主线程main,为前台线程
System.out.println(Thread.currentThread().getName() + "\t\t" + i);
}
}
//线程体
private static class PriorityThreadTask implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
System.out.println(Thread.currentThread().getName() + "\t" + i);
}
}
}
public static void testThreadPriority() {
Thread thread0 = new Thread(new PriorityThreadTask());
Thread thread1 = new Thread(new PriorityThreadTask());
// System.out.println(Thread.currentThread().getPriority());
// System.out.println(thread0.getPriority());
// System.out.println(thread1.getPriority());
thread0.setPriority(Thread.MAX_PRIORITY);//设置最大的优先级
thread0.start();
thread1.setPriority(Thread.MIN_PRIORITY);//设置最小的优先级
thread1.start();
}
}
线程安全问题
让多个线程共享资源中的安全问题:
public class ThreadDemo4 {
public static void main(String[] args) {
Ticket ticket = new Ticket(100);
SellTask task = new SellTask(ticket);
new Thread(task, "John").start();//线程
new Thread(task, "Mary").start();//线程体是一样的,用一样的变量数据
new Thread(task, "Lucy").start();
new Thread(task, "Tony").start();
new Thread(task, "Lily").start();
}
private static class Ticket {
private int amount;
public Ticket(int amount) {
this.amount = amount;
}
public int getAmount() {
return amount;
}
public void buy(int amount) {
if (this.amount < amount) {
throw new IllegalArgumentException("余量不足!");
}
// 假设校验花费一些时间
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 通过校验成功购票
this.amount -= amount;
String name = Thread.currentThread().getName();
System.out.println(name + "购买成功,剩余数量" + this.amount);
}
}
//卖票多线程
private static class SellTask implements Runnable {
private Ticket ticket;
public SellTask(Ticket ticket) {
this.ticket = ticket;
}
@Override
public void run() {
ticket.buy(1);
}
}
}
线程同步
◼同步
对在一个系统中所发生的事件之间进行协调,在时间上出现一致性与统一化的现象;
◼加锁
1.加锁 –> 修改 –> 解锁
2.加锁机制可保障在任一时刻只有一个线程可以进入共享资源的代码区(临界区)。
synchronized
在同步代码块、同步方法执行结束,或者是异常终止时,当前线程会自动解锁。
◼同步代码块
synchronized(obj) { ... }
obj代表锁定的目标(同步监视器),它可以是任意的对象; 考虑到它的作用,建议采用并发访问的资源作为同步监视器;
◼同步方法
public synchronized void fun() { ... }//访问方法时会排队
无需显示指定同步监视器,在成员方法中它默认为this,在静态方法中它默认为当前的类。
◼ synchronized的缺点
1.将加锁及解锁的过程固化了,便捷性有余,但灵活性不足;
2.某个线程在访问同步代码时被阻塞了,其他线程只能等待,影响程序的执行效率;
3.在访问共享资源时,对于多个线程同时读的场景,实际不会产生任何冲突,但是synchronized不会区分这种场景,依然做加锁处理,还是影响程序的执行效率。
Lock接口
| Lock(接口) | |
|---|---|
void lock() | 获取锁 |
void unlock() | 释放锁 |
boolean tryLock(long time, TimeUnit unit) | 获取锁,若超时则返回false |
| ReadWriteLock(接口) | 读写锁 |
|---|---|
Lock readLock() | 返回用于读取的锁 |
Lock writeLock() | 返回用于写入的锁 |
- ReentrantLock类、ReentrantReadWriteLock类分别是Lock和ReadWriteLock接口的常用实现类;
- ReentrantLock类(重入锁),就是支持重新进入的锁,表示该锁可以支持一个线程对资源重复加锁。
| 特性 | synchronized | Lock |
|---|---|---|
| 锁对象 | 锁定指定的对象 | 锁定 Lock 实例本身 |
| 实现机制 | JVM 内置的 monitor | 基于 AQS 的 Java 实现 |
| 等待队列 | 一个等待队列 | 分离的同步队列 + Condition 队列 |
| 灵活性 | 相对固定 | 更灵活,支持多个 Condition |
同步代码块示例
对线程安全问题中的代码改进而来:修改添加一处
synchronized (this) {
// 通过校验成功购票
this.amount -= amount;
String name = Thread.currentThread().getName();
System.out.println(name + "购买成功,剩余数量" + this.amount);
}
同步方法示例
对线程安全问题中的代码改进而来:修改添加一处
public synchronized void buy(int amount) {...}
同步锁示例
对线程安全问题中的代码改进而来:修改添加两处
private static class Ticket {
private Lock lock = new ReentrantLock();//锁对象实例化
private int amount;
public Ticket(int amount) {
this.amount = amount;
}
public int getAmount() {
return amount;
}
public void buy(int amount) {
if (this.amount < amount) {
throw new IllegalArgumentException("余量不足!");
}
// 校验花费一些时间
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.lock();//加锁
try {
// 通过校验成功购票
this.amount -= amount;
String name = Thread.currentThread().getName();
System.out.println(name + "购买成功,剩余数量" + this.amount);
} finally {
lock.unlock();
}
}
}
死锁
当两个线程互相等待对方释放同步监视器时会发生死锁,应避免这种情况的出现:
◼避免多次锁定 尽量避免同一个线程对多个同步监视器进行锁定;
◼按相同的顺序加锁 如果多个线程需要对多个同步监视器加锁,则应该保证它们以相同的顺序请求加锁;
◼使用可以超时释放的锁 调用Lock对象的tryLock(time,unit)方法,当超过指定时间后它会自动释放锁。
示例
public class ThreadDemo8 {
public static void main(String[] args) {
String a = "A";
String b = "B";
new Thread(new FirstTask(a, b)).start();
new Thread(new SecondTask(a, b)).start();
}
//线程1-先锁a再锁b
private static class FirstTask implements Runnable {
private Object a;
private Object b;
public FirstTask(Object a, Object b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
synchronized (a) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
System.out.println("First");
}
}
}
}
//线程2-先锁b再锁a
private static class SecondTask implements Runnable {
private Object a;
private Object b;
public SecondTask(Object a, Object b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
synchronized (b) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (a) {
System.out.println("Second");
}
}
}
}
}
9.3 线程高级特性
线程通信
1.在某些业务中,A线程负责修改数据,B线程负责使用数据; 2.在数据修改前,B线程处于等待状态,直至得到A线程的通知; 3.在数据修改后,A线程通过某种机制,通知B线程去使用数据。
线程通信的前提是要支持并发读写数据,所以线程通信前必须要对共享资源加锁。
线程通信(synchronized)
synchronized(obj) { ... }//同步代码块对对象加锁
synchronized void fun() { ... }//同步方法对方法加锁
| Object | |
|---|---|
void wait() | 调用该方法的线程进入”等待”状态,并释放此对象的锁 |
void wait(long timeMillis) | 同上,但最长等待timeMillis毫秒 |
void notify() | 通知随机一个在此对象上等待的线程,使其从wait()返回 |
void notifyAll() | 通知所有在此对象上等待的线程,使其从wait()返回 |
例如
synchronized(obj) {
obj.wait());
}
/**
* 线程通信(synchronized)
*/
public class ThreadDemo9 {
public static void main(String[] args) {
Product product = new Product(0);
for (int i = 0; i < 100; i++) {
new Thread(new BuyTask(product), "顾客" + i).start();
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(new SellTask(product), "卖家").start();
}
//商品
private static class Product {
private int amount;
public Product(int amount) {
this.amount = amount;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
}
//买家购买
private static class BuyTask implements Runnable {
private Product product;
public BuyTask(Product product) {
this.product = product;
}
@Override
public void run() {
synchronized (product) {//1、首先获得锁
String name = Thread.currentThread().getName();
while (product.getAmount() == 0) {//2、获得锁后但是库存为0
try {
System.out.println(name + "已做好准备,等待抢购...");
product.wait();//3、释放锁并等待被唤醒
//被唤醒后,需要重新获得锁才能从这里继续执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//获得锁后且库存不为0就可以继续执行
product.setAmount(product.getAmount() - 1);//购买商品
System.out.println(name + "抢到1件商品,剩余库存" + product.getAmount());
}// 退出 synchronized 块,释放锁
}
}
//卖家售卖
private static class SellTask implements Runnable {
private Product product;
public SellTask(Product product) {
this.product = product;
}
@Override
public void run() {
synchronized (product) {
product.setAmount(10);
String name = Thread.currentThread().getName();
System.out.println(name + "上家10件商品,剩余库存" + product.getAmount());
product.notifyAll();
}
}
}
}
线程通信(Lock)
Condition condition = lock.newCondition();//返回一个Condition(接口)
| Condition(接口) | |
|---|---|
void await() | 调用该方法的线程进入”等待”状态 |
void await(long time, TimeUnit unit) | 同上,但最长等待time时间,unit为时间单位 |
void signal() | 唤醒随机一个在此Condition上等待的线程 |
void signalAll() | 唤醒所有在此Condition上等待的线程 |
线程通信(Lock)与线程通信(synchronized)相比修改的代码:
private static Lock lock = new ReentrantLock();
private static Condition condition = lock.newCondition();
@Override
public void run() {
lock.lock();
try {
String name = Thread.currentThread().getName();
while (product.getAmount() == 0) {
try {
System.out.println(name + "已做好准备,等待抢购...");
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
product.setAmount(product.getAmount() - 1);
System.out.println(name + "抢到1件商品,剩余库存" + product.getAmount());
} finally {
lock.unlock();
}
}
@Override
public void run() {
lock.lock();
try {
String name = Thread.currentThread().getName();
while (product.getAmount() == 0) {
try {
System.out.println(name + "已做好准备,等待抢购...");
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
product.setAmount(product.getAmount() - 1);
System.out.println(name + "抢到1件商品,剩余库存" + product.getAmount());
} finally {
lock.unlock();
}
}
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 线程通信(Lock)
*/
public class ThreadDemo10 {
private static Lock lock = new ReentrantLock();
private static Condition condition = lock.newCondition();
public static void main(String[] args) {
Product product = new Product(0);
for (int i = 0; i < 100; i++) {
new Thread(new BuyTask(product), "顾客" + i).start();
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(new SellTask(product), "卖家").start();
}
private static class Product {
private int amount;
public Product(int amount) {
this.amount = amount;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
}
private static class BuyTask implements Runnable {
private Product product;
public BuyTask(Product product) {
this.product = product;
}
@Override
public void run() {
lock.lock();
try {
String name = Thread.currentThread().getName();
while (product.getAmount() == 0) {
try {
System.out.println(name + "已做好准备,等待抢购...");
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
product.setAmount(product.getAmount() - 1);
System.out.println(name + "抢到1件商品,剩余库存" + product.getAmount());
} finally {
lock.unlock();
}
}
}
private static class SellTask implements Runnable {
private Product product;
public SellTask(Product product) {
this.product = product;
}
@Override
public void run() {
lock.lock();
try {
product.setAmount(10);
String name = Thread.currentThread().getName();
System.out.println(name + "上家10件商品,剩余库存" + product.getAmount());
condition.signalAll();
} finally {
lock.unlock();
}
}
}
}
阻塞队列
生产者消费者模式
1.某个模块负责产生数据,另一个模块负责处理数据; 2.产生数据的模块被称为生产者,处理数据的模块被称为消费者; 3.需要有一个缓冲区位于生产者与消费者之间,作为沟通的桥梁; 4.生产者只负责把数据放入缓冲区,而消费者从缓冲区取出数据。
生产者 –》 缓冲区 –》 消费者
BlockingQueue接口
BlockingQueue是Queue的子接口,它的主要作用是作为线程通信的工具!
BlockingQueue内部已经实现了线程安全
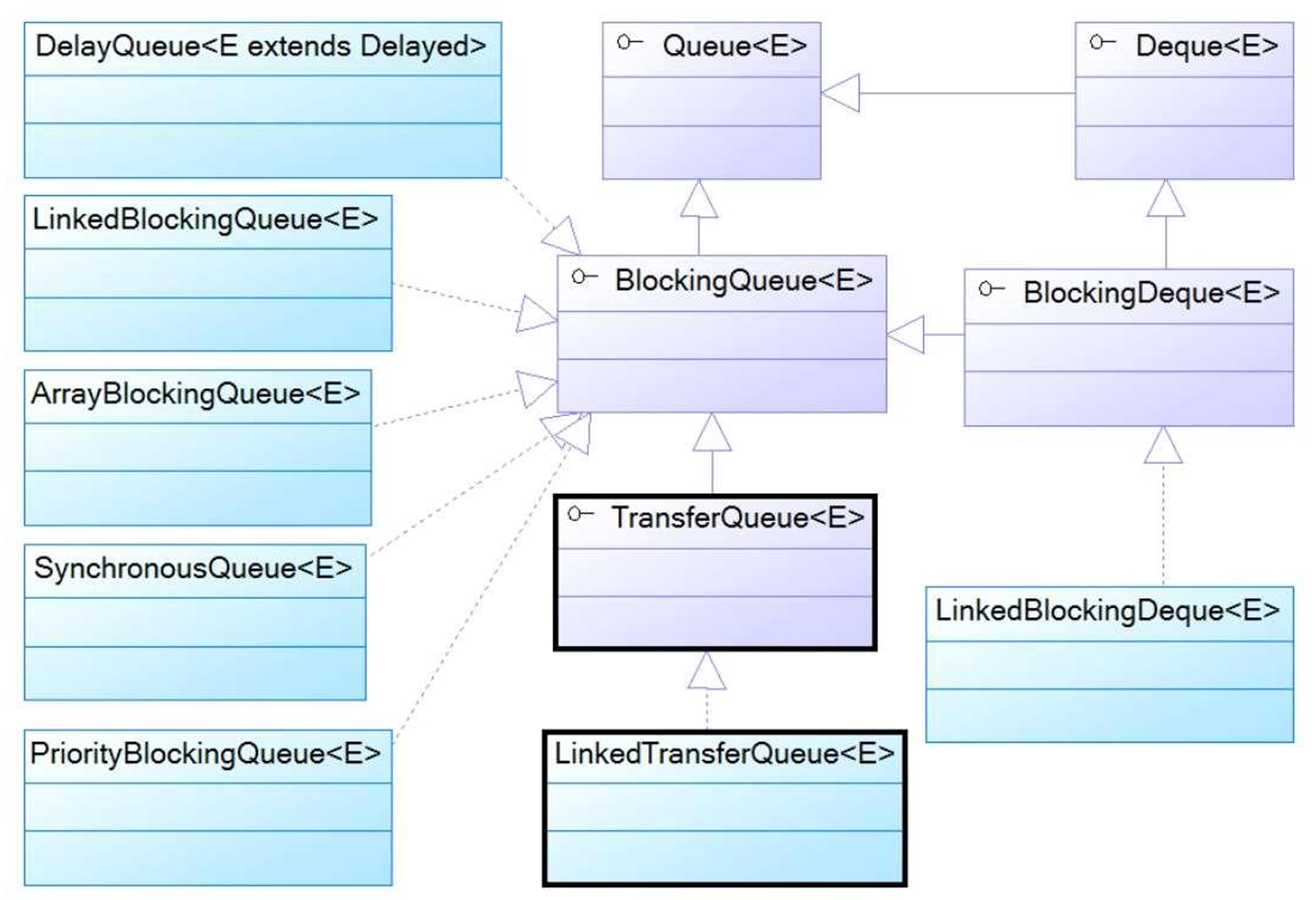
BlockingQueue增加了2个支持阻塞的方法:
void put(E e):尝试把元素e入列,如果该队列的元素已满,则阻塞该线程;
void take():尝试从队列的头部出列,如果该队列的元素已空,则阻塞该线程;
阻塞队列代码示例:生产者-消费者模式
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.BlockingQueue;
/**
* 阻塞队列
*/
public class ThreadDemo11 {
public static void main(String[] args) {
BlockingQueue<Long> queue = new ArrayBlockingQueue<>(10);
new Thread(new Producer(queue), "P1").start();
new Thread(new Producer(queue), "P2").start();
new Thread(new Producer(queue), "P3").start();
new Thread(new Producer(queue), "P4").start();
new Thread(new Producer(queue), "P5").start();
new Thread(new Customer(queue), "C1").start();
new Thread(new Customer(queue), "C2").start();
new Thread(new Customer(queue), "C3").start();
}
//生产者
private static class Producer implements Runnable {
private BlockingQueue<Long> queue;//依赖接口-松耦合
public Producer(BlockingQueue<Long> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(new Random().nextInt(1000));
queue.put(System.currentTimeMillis());
String name = Thread.currentThread().getName();
System.out.println(name + "生产了一条数据,剩余" + queue.size());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//消费者
private static class Customer implements Runnable {
private BlockingQueue<Long> queue;//依赖接口-松耦合
public Customer(BlockingQueue<Long> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
Thread.sleep(new Random().nextInt(1000));
queue.take();
String name = Thread.currentThread().getName();
System.out.println(name + "消费了一条数据,剩余" + queue.size());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
线程组
ThreadGroup类代表线程组,它可以包含一批线程,并对这些线程进行统一的管理:
没有孤立的线程:1.每个线程都有对应的线程组,若程序未显示指定线程的线程组,则该线程属于默认线程组;
2.默认情况下,子线程与它的父线程属于同一个线程组,而main线程归则属于main线程组;
3.一旦线程加入了某个线程组,则该线程将一直属于这个线程组,中途不允许修改其线程组。
创建线程组
◼ ThreadGroup的构造器
public ThreadGroup(String name)//指定名字
public ThreadGroup(ThreadGroup parent, String name)//指定父线程组和名字
◼ Thread的构造器
public Thread(ThreadGroup group, String name)//指定线程组和线程名
public Thread(ThreadGroup group, Runnable target)//指定线程组和线程体
public Thread(ThreadGroup group, Runnable target, String name)//都指定
使用线程组
ThreadGroup中常用的处理线程的方法包括:
1.返回线程组的名称;
2.返回当前线程组的父线程组;
3.中断此线程组中所有的线程;
4.设置(返回)线程组的最高优先级;
5.设置(返回)线程组为后台线程组。
异常处理器
1. UncaughtExceptionHandler接口代表异常处理器;
2. Thread类提供了set方法来指定该线程的异常处理器;
3. ThreadGroup类默认已经实现了这个异常处理器接口;
结论:当一个线程抛出异常时,JVM会先查找该线程对应的异常处理器,若找到则调用该异常处理器来处理异常,否则JVM将调用该线程所属线程组的方法来处理这个异常。
/**
* 线程组
*/
public class ThreadDemo12 {
public static void main(String[] args) {
// 获得主线程的线程组
ThreadGroup g = Thread.currentThread().getThreadGroup();
System.out.println(g.getName() + "," + g.isDaemon() + "," + g.activeCount());// 线程组名字,是否后台线程组,活跃的线程数量
g.list();
// 子线程的线程组和主线程是一个
Thread thread = new Thread(new ThreadTask());
thread.start();
System.out.println(thread);
// 自定义的线程组
g = new ThreadGroup("TEST");
g.setDaemon(true);//声明是后台线程组
thread = new Thread(g, new ThreadTask());
thread.start();
System.out.println(thread);
// 销毁的后台线程组
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(g.isDestroyed());// 销毁
// 异常处理器
Thread.setDefaultUncaughtExceptionHandler(
new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println(t + " -> " + e);
}
}
);
System.out.println(3 / 0);
}
// 线程
private static class ThreadTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis());
}
}
}
线程池
◼启动线程的成本是比较高的,通过线程池可以实现线程的复用,从而提高性能;
◼线程池可以控制程序中的线程的数量,避免超出系统的负荷,导致系统的崩溃。
1.创建线程池之后,它会自动创建一批空闲的线程; 2.程序将线程体传给线程池,它就会启动一个空闲的线程来执行该线程体; 3.当线程体执行结束后,该线程并不会死亡,而是变回空闲状态继续使用。
创建线程池
1.ExecutorService接口代表线程池;
2.ScheduledExecutorService是其子接口,代表可执行定时任务的线程池;
3.Executors是一个工厂类,该类中包含了若干个静态方法,用来创建线程池:
ExecutorService newFixedThreadPool(int nThreads)//指定线程数量
ScheduledExecutorService newScheduledThreadPool(int corePoolSize)//创建定时任务的线程池
使用线程池
◼ ExecutorService 线程池
Future<?> submit(Runnable task); // 默认线程的run方法没有返回值,所以这里这个方法return null,
<T> Future<T> submit(Runnable task, T Result); // return result
<T> Future<T> submit(Callable<T> task); //Callable线程体 return call()
◼ ScheduledExecutorService 执行定时任务的线程池
ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
//传入线程体,延迟的时间和单位
<V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
//传入Callable线程体,延迟的时间和单位
ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
//传入线程体,第一次延迟的时间,固定周期和单位
ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
//传入线程体,第一次延迟的时间,执行结束后delay单位后再执行和单位
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 线程池
*/
public class ThreadDemo13 {
//一般定义为成员,来复用
private static ExecutorService threadPool = Executors.newFixedThreadPool(3);//线程池
private static ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(3);//执行定时任务的线程池
//主程序入口
public static void main(String[] args) {
//线程
Runnable threadTask = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " execute a thread task.");
}
};
//或者使用lambda表达式
//Runnable threadTask = () ->
// System.out.println(Thread.currentThread().getName() + " execute a thread task.");
//使用线程池
for (int i = 0; i < 10; i++) {
threadPool.submit(threadTask);
}
//线程
Runnable scheduledTask = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " execute a scheduled task.");
}
};
//使用定时线程池
for (int i = 0; i < 5; i++) {
scheduledPool.scheduleAtFixedRate(scheduledTask, 5, 3, TimeUnit.SECONDS);
}
}
}
ForkJoinPool
1.Fork/Join是一种思想,旨在充分利用多核资源,用于执行并行任务;
2.ForkJoinPool是ExecutorService(线程池)的实现类,是上述思想的实现;
3.它的做法是,将一个大的任务分割成若干个小任务,最终汇总每个小任务结果,从而得到大任务的结果。
创建ForkJoinPool
◼构造器
ForkJoinPoll(int parallelism)//根据指定的并行级别,创建一个ForkJoinPool;
ForkJoinPool()//根据计算机的核心数,创建一个ForkJoinPool。
◼使用ForkJoinPool
◼常用方法
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {}
◼ ForkJoinTask
1.代表一个可以并行执行的任务,是Future的实现类;
2.RecursiveAction、RecursiveTask是它的子类;
3.RecursiveAction代表没有返回值的任务,RecursiveTask代表有返回值的任务。
可以按照下面的模板来写:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* ForkJoinPool
*/
public class ThreadDemo14 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int[] nums = new int[100];
for (int i = 1; i <= 100; i++) {
nums[i - 1] = i;
}
ForkJoinPool pool = new ForkJoinPool();
Future<Integer> future = pool.submit(new FjTask(nums, 0, nums.length - 1));//主线程创建根任务 (0-99)
System.out.println(future.get());
}
private static class FjTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 10;//定义一个拆分阈值
private int[] nums;//数组,用于传入数据
private int start, end;//定义拆分的段落
public FjTask(int[] nums, int start, int end) {
this.nums = nums;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//printf以格式化的方式打印。和c语言相似,%-25s指25宽,-指左对齐
System.out.printf("%-25s\t%2d,%2d\n", Thread.currentThread().getName(), start, end);
Integer sum = 0;
//小于阈值,开始计算
if (end - start < THRESHOLD) {
for (int i = start; i <= end; i++) {
sum += nums[i];
}
} else {
int middle = (start + end) / 2;
FjTask left = new FjTask(nums, start, middle);
FjTask right = new FjTask(nums, middle + 1, end);
left.fork();//将left任务放入工作队列,等待工作线程执行 compute()
right.fork();//将right任务放入工作队列,等待工作线程执行 compute()
sum = left.join() + right.join();
}
return sum;
}
}
}
ThreadLocal
ThreadLocal是一个工具类,可以将数据绑定到当前线程上,从而实现线程间数据的隔离:
public void set(T value) {}//将数据绑定到当前线程之上
public T get() {}//返回当前线程已绑定的数据
public void remove() {}//删除当前线程已绑定的数据
public class ThreadDemo15 {
//创建ThreadLocal对象
private static ThreadLocal<Object> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(new ThreadTask(100)).start();
new Thread(new ThreadTask(200)).start();
new Thread(new ThreadTask(300)).start();
}
public static void first() {
System.out.println(Thread.currentThread().getName() + " execute first()");
second();
}
public static void second() {
System.out.println(Thread.currentThread().getName() + " execute second()");
third();
}
public static void third() {
System.out.println(Thread.currentThread().getName() + " execute third()");
System.out.println(Thread.currentThread().getName() + " binding value " + threadLocal.get());//threadLocal.get()返回当前线程已绑定的数据
}
private static class ThreadTask implements Runnable {
private Object value;
public ThreadTask(Object value) {
this.value = value;
}
@Override
public void run() {
threadLocal.set(value);//将数据value绑定到当前线程之上
first();
}
}
}
线程安全的集合
包装不安全的集合
对于传统的集合类,可以通过Collections将线程不安全的集合包装成线程安全的集合:
public static <T> Set<T> synchronizedSet(Set<T> s) {}
public static <T> List<T> synchronizedList(List<T> list) {}
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {}
//实现原理是在原本的集合上进行加锁实现线程安全
线程安全的集合类如下:
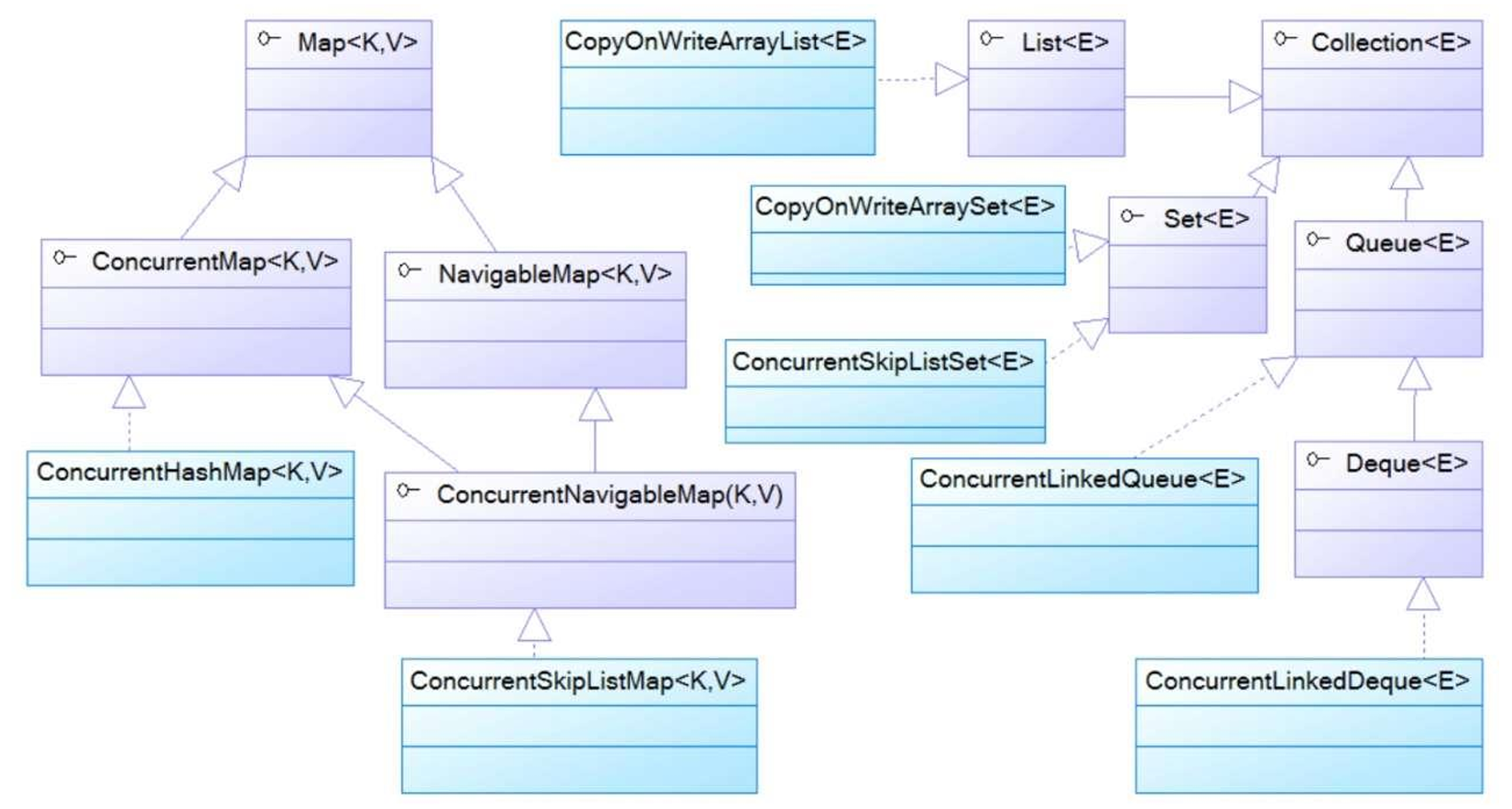
上面这些类位于java.util.concurrent包下,实现机制:
◼ Concurrent开头的集合类
1.支持多线程的并发访问;
2.通过加锁处理,保证了并发写入的安全性,而并发读取是无需加锁的;
◼ CopyOnWrite开头的集合类
1.并发读取时,直接读取集合本身,无需加锁;
2.并发写入时,该集合会在底层复制一份新数组,然后对新数组进行写入操作。
10. 网络编程
10.1 网络基础
基于TCP/IP协议的通信
◼ TCP/IP协议 1.TCP/IP协议会在通信两端建立连接(虚拟链路),用于发送和接收数据; 2.TCP/IP协议是一种可靠的网络协议,它通过重发机制来保证这种可靠性;
◼通信的实现 1.ServerSocket用于监听来自客户端的连接,当没有连接时,它处于阻塞状态; 2.客户端使用Socket连接到指定的服务器。
基于UDP协议的通信
◼ UDP协议 1.UDP协议不会在通信两端建立连接(虚拟链路),而是直接发送数据; 2.UDP协议是一种不可靠的网络协议,但是这种协议的通信效率非常高;
◼通信的实现 1.DatagramSocket用于两端的通信,它不负责维护状态、不产生IO流,仅仅是发送或 接收数据报; 2.DatagramPacket代表数据报。
Java使用Socket对象来代表两端的通信端口,并通过Socket产生IO流来进行网络通信。
InetAddress类
InetAddress类用于表达网络的地址
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
/**
* InetAddress
*/
public class InetAddressDemo {
public static void main(String[] args) throws IOException {
//创建一个域名的实例
InetAddress baidu = InetAddress.getByName("www.baidu.com");
//获取ip
System.out.println(baidu.getHostAddress());
//是否可达
System.out.println(baidu.isReachable(2000));
//创建一个ip的实例
InetAddress local = InetAddress.getByAddress(new byte[]{127, 0, 0, 1});
//获取域名,因为实例没有主机名,因此会返回ip
System.out.println(local.getHostName());
//是否可达
System.out.println(local.isReachable(2000));
}
}
10.2 网络通信
基于TCP协议的通信-1
TcpServer
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
public class TcpServer {
public static void main(String[] args) {
try {
//实例化ServerSocket,并指定端口9000
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
//accept在没有客户端连接时处于阻塞状态
Socket serversocket = serverSocket.accept();
System.out.println("请求: " + serversocket.toString());
//serversocket.getOutputStream()向客户端输出
PrintStream ps = new PrintStream(serversocket.getOutputStream());
ps.println("Welcome " + serversocket.getInetAddress().getHostAddress());
serversocket.close();//不用显示关闭流(Stream),socket关闭的时候会自动关闭
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
TcpClient
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.Socket;
public class TcpClient {
public static void main(String[] args) {
try {
Socket socket = new Socket("127.0.0.1", 9000);
//创建流获取服务端的信息
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String line = br.readLine();
System.out.println(line);
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
基于TCP协议的通信-2
聊天式的案例,支持多客户端同时在线和实时消息广播。
服务端和客户端都要并发,需要实现多线程。
TcpServer
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TcpServer {
//线程池
public static ExecutorService threadPool = Executors.newFixedThreadPool(10);
//记录客户端
public static List<Socket> socketList = Collections.synchronizedList(new ArrayList<>());
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
Socket socket = serverSocket.accept();
//存入客户端信息
socketList.add(socket);
//用线程池创建线程
threadPool.submit(new ThreadTask(socket));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
class ThreadTask implements Runnable {
private Socket socket;
private BufferedReader reader;
public ThreadTask(Socket socket) {
this.socket = socket;
try {
//创建输入流
this.reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void run() {
try {
String line;
while ((line = reader.readLine()) != null) {
//遍历所有客户端
for (Socket client : TcpServer.socketList) {
String from = socket.getInetAddress().getHostAddress() + ":" + socket.getPort();
String content = from + "说: " + line;
//创建输出流,注意println,在输入回车后结束该次输入,不带ln会导致无法判断结尾
new PrintStream(client.getOutputStream()).println(content);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
TcpClient
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TcpClient {
//线程池
public static ExecutorService threadPool = Executors.newFixedThreadPool(3);
public static void main(String[] args) {
try {
Socket socket = new Socket("127.0.0.1", 9000);
//创建读线程
threadPool.submit(new ReadTask(socket));
//创建写线程
threadPool.submit(new WriteTask(socket));
} catch (Exception e) {
e.printStackTrace();
}
}
}
class ReadTask implements Runnable {
private Socket socket;
private BufferedReader reader;
public ReadTask(Socket socket) {
this.socket = socket;
try {
//创建输入流
reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void run() {
try {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
class WriteTask implements Runnable {
private Socket socket;
private PrintStream writer;
public WriteTask(Socket socket) {
this.socket = socket;
try {
//创建输出流
writer = new PrintStream(socket.getOutputStream());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void run() {、
//创建键盘输入流
Scanner scanner = new Scanner(System.in);
String line;
while ((line = scanner.nextLine()) != null) {
//将内容输入
writer.println(line);
}
}
}
基于UDP协议的通信
基于UDP的广播通知系统
UdpServer
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class UdpServer {
//创建线程池
public static ExecutorService threadPool = Executors.newFixedThreadPool(10);
//曾经连接过的客户
public static List<InetSocketAddress> addressList = new ArrayList<>();
public static void main(String[] args) {
try {
DatagramSocket socket = new DatagramSocket(9001);
// 随时通知
threadPool.submit(new SendTask(socket));
// 接受注册
byte[] buffer = new byte[1024];
//创建数据报接受数据存入buffer
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
while (true) {
socket.receive(packet);
addressList.add((InetSocketAddress) packet.getSocketAddress());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
class SendTask implements Runnable {
private DatagramSocket socket;
public SendTask(DatagramSocket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
Scanner scanner = new Scanner(System.in);
String line;
while ((line = scanner.nextLine()) != null) {
for (InetSocketAddress isa : UdpServer.addressList) {
byte[] buffer = line.getBytes();
DatagramPacket packet = new DatagramPacket(
buffer, buffer.length, isa.getAddress(), isa.getPort());
socket.send(packet);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
UdpClient
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class UdpClient {
public static ExecutorService threadPool = Executors.newFixedThreadPool(3);
public static void main(String[] args) {
try {
DatagramSocket socket = new DatagramSocket();
// 注册
DatagramPacket packet = new DatagramPacket(
new byte[]{1}, 1, InetAddress.getByName("127.0.0.1"), 9001);
socket.send(packet);
// 接收
threadPool.submit(new ReceiveTask(socket));
} catch (Exception e) {
e.printStackTrace();
}
}
}
class ReceiveTask implements Runnable {
private DatagramSocket socket;
public ReceiveTask(DatagramSocket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
byte[] buffer = new byte[1024];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
while (true) {
socket.receive(packet);
String line = new String(packet.getData(), 0, packet.getLength());
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Problem:
Windows终端默认使用GBK编码编译Java文件,如果Java文件保存为UTF-8编码,会导致中文字符无法正确识别。
编译时指定编码
javac -encoding utf-8 HelloWorld.java
default public private protected final abstract static synchronized
1. 方法链的实现原理
.方法().方法() 这种连续调用叫做方法链或流式API。实现原理是:
public class FileProcessor {
private String path;
public FileProcessor setPath(String path) {
this.path = path;
return this; // 关键:返回当前对象
}
public FileProcessor filter(String extension) {
// 过滤逻辑
return this; // 关键:返回当前对象
}
public void process() {
// 处理逻辑
}
}
// 使用方式
new FileProcessor().setPath("C:/work").filter(".txt").process();
关键点:每个方法都返回 this 或新的相关对象,这样就能继续调用其他方法。
面向接口编程(Interface-Oriented Programming)
java
// 好的做法 – 面向接口
private BlockingQueue<Long> queue;
// 不好的做法 – 面向实现
private ArrayBlockingQueue<Lo



